- 构建一个任务型对话系统:调研
- 构建一个任务型对话系统:系统定义
- 构建一个任务型对话系统:系统设计
引言
本文由几部分组成,分别调研相应领域的进展以及做出个人认为最优的选择。各部分之间几乎没有关联。
框架
管道式(pipeline)任务型对话系统通常由六大模块组成,每个模块的功能及其算法实现几乎都不相同,外加还需要维护系统中其他模块,例如用户模拟器、multi-agent 交互、数据库连接、网络编程等。这意味着要想从头开发一个任务型对话系统需要熟练使用多种算法,并且了解系统的组成。一个框架可以很好地帮助开发者预先创建上述模块。为此,本人调研了几个框架:PyDial,ConvLab,ConvLab-2,Rasa 和 Plato。
PyDial (Ultes et al. 2017) 基于 python2 开发,现已停止维护,因此不作考虑。ConvLab(Lee et al. 2019) 是 ConvLab2 的前身,因此也不做考虑。ConvLab-2 (Zhu et al. 2020) 基于 python3 开发,并且提供了 pipeline 和 end-to-end 的实现方式以及各个模块的算法实现。总的来说,ConvLab2 是一个比较全面的平台,不过它并不面向开发者,而是面向科研人员,旨在为他们提供一套简单、可控、可复现的环境。ConvLab2 也不是很适合用于开发。
Rasa (Bocklisch et al. 2017) 是丰富的对话系统库,它提供了自然语言理解、对话管理以及自然语言生成几项功能,并且对开发者十分友好。Rasa 还支持在线学习(online learning),即用户可以与 agent 交互以此评估它的行为。然而,Rasa 似乎是一个借助 AI 技术和模板对话强行投入生产环境的商品。它使用一套自定义的话术(story)完成人机对话,关于这套话术的配置需要开发人员自行编写,但不需要理解技术细节,Rasa 会自动完成训练。这似乎对非 AI 领域的开发人员比较友好,从 Rasa 团队写的博客中也可以观察到。
2016 年时,博客写到:除了炒作之外,在构建对话软件之前还需要做很多事。就目前而言,只能结合一点 AI 技术以及大量的人工编码。不过对于风投而言,新的平台意味着是可以绑定和拆分服务的新机会,或者是大公司的新战场。因此,即使没有真正的技术突破,至少还可以赚到一些钱。那在当前阶段,该如何实现这么一个类 AI 的对话系统产品呢?他们的回答是他们也还不知道。
2017 年,他们似乎找到了方法。博客写到。。。
Rasa 探索了使用 AI 技术和模板构建对话系统的方法,然而它大量依赖话术,并且其架构与传统的任务型对话系统架构相去甚远。
Plato (Papangelis et al. 2020) 由 Uber 公司研发,同样提供了 pipeline 和 end-to-end 的实现方式以及各模块的算法实现。此外,它还支持 multi-agent 交互(在计划中)。Plato 由配置文件驱动,只要在 yml 文件中填写对应的参数以及模块名,就能够拼装成一个完整的对话系统,这与 Rasa 十分类似。然而,它所支持的算法较为有限,并且这些算法也不是当前最新的,最关键的是该项目已被废弃。
最终,我们决定从头开始构建一个对话系统。
预训练模型
预训练模型凭借着海量的训练数据,可以获得优质的单词表征。在众多任务中取得了不错的成绩。近几年,在任务导向对话中也有不少研究工作使用预训练模型,实验结果说明其前景广阔(Zhang et al. 2020)。因此,本项工作将直接使用预训练模型作为编码器,而不是传统的 RNN。
经过调研,我们打算使用 TOD-BERT(Wu et al. 2020),它是一个基于一系列任务导向对话数据集的大规模预训练模型。简单来说,在训练时,该模型使用两个额外符号明确地表示人机交互过程,即 [usr] 和 [sys]。这是因为人机对话与网络上的通用文本具有明显区别,人机对话的特点是一轮对话包括一条用户语句以及一条系统回复。
以下是调研过程中看到的一些其他的论文。
(Mehri et al. 2019)对比四种预训练目标,其中两种为新提出的方法,期望通过这两种方法可以获得更健壮、更通用的对话上下文表征。(Mehri and Eskenazi 2019)。。。
- DialoGLUE 中有写到两个专用于对话的预训练模型
- ConveRT: Efficient and accurate conversational representations from transformers
- Dialogue transformers
炼丹
对输入序列特性的调研
近期的工作已经展示了当 RNNs 被用作解决通用语言处理任务时,例如语言建模和机器翻译,它可以隐式地捕获和利用层次信息。相比之下,非循环结构的神经网络(CNN、Transformer)也在众多 NLP 任务中受到关注。为了比对两种结构在建模层次结构方面的能力,同时为了证明“循环”是否为关键因素,(Tran, Bisazza, and Monz 2018) 分别比对了主谓一致以及逻辑推理两项实验的结果。他们观察到在主谓一致实验中,无论难度(词距、一致因子距离)如何,LSTM 均强于 Transformer;在逻辑推理实验中,LSTM 在大部分情况下均强于 Transformer。他们认为当层次结构对任务很重要时,循环是模型的一种特性,不应该为了运行效率而牺牲它。
(Tang et al. 2018) 却得到了与 (Tran, Bisazza, and Monz 2018) 不同的结果(Transformer 略优于 LSTM),在分析上述实验之后,他们发现 (Tran, Bisazza, and Monz 2018) 使用了迷你版的 Transformer。在做以下退化之后,他们得到了与 (Tran, Bisazza, and Monz 2018) 类似的结果,退化步骤为:layers(8→4);embedding size(512→128);head(8→2);dropout(0.1→0.2)……
综上所述,在捕获层次结构的信息时,LSTM 与 Transformer 的能力应该相差无几。
由于 DST 任务对层次结构信息的要求不是很高,因此我们选择基于 Transformer 的预训练模型作为编码器。
注意:下述论文分析的是模型结构的选择以及注意力机制的运用,是否会影响对话系统使用其可用的信息。
(Sankar et al. 2019)对神经回复生成模型提出疑问:“神经语言模型是否有效地使用了对话历史?”为此他们进行实证研究,其中心假设为:如果模型对破坏他们的扰动不敏感,那么他们就很少使用某些类型的信息。令人担忧的是,他们发现:1)基于 rnn 或 Transformer 的 seq2seq 模型均对本工作中使用的扰动不敏感;2)即使做出巨大的扰动,例如随机排序或者逆序单词,二者仍旧极其地不敏感(见表 1);3)循环模型对对话历史中的语句顺序更敏感,这表明它比 Transformer 更易于捕获对话的多样性(conversation dynamics)。
通过对比模型困惑度的增衰,他们观察到:1)在大多数例子中,模型困惑度只有微小的变化,这表明他们远没有使用其可用的所有信息;2)Transformers 对单词重排序不敏感,这意味着其可以学习词袋类型的表征?;3)观察 Only Last 一列,seq2seq_lstm_att 和 transformers 比普通 seq2seq 使用更多对话历史的信息;4)虽然 Transformers 收敛更快并能够达到更低的测试集困惑度,但是他们似乎没有捕获对话的多样性。 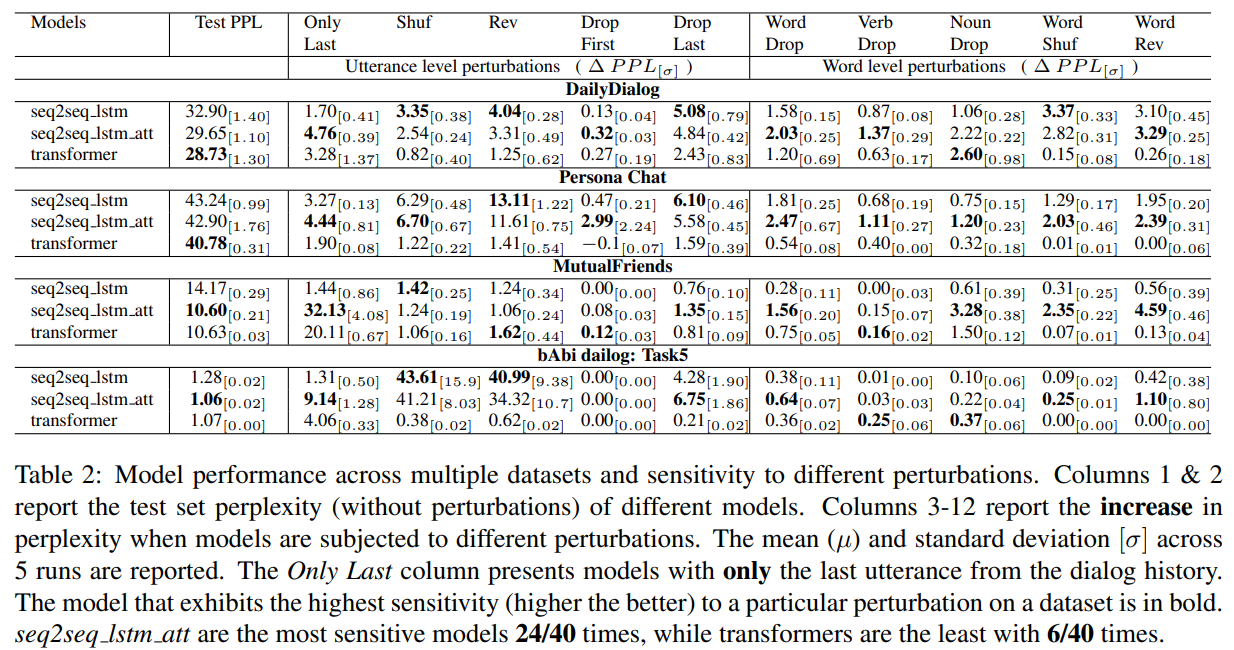
如何表示对话历史
值得注意的是,以往很多工作构建的是 dialogue-level DST,此类模型在每一轮都会重新预测完整的对话状态。在这种情况下,对话历史就是一件必需品,这是因为其中包含了以往的用户目标。如果不提供对话历史,模型就无法提取完整的对话状态。而对于 turn-level DST 模型,对话历史则是不必要的。
传统 DST 模型一般将完整的对话历史作为编码器的输入。虽然可以将对话历史视为补充信息,但是其中也夹杂着大量的无用特征,致使其成为模型的负担(例如无法捕获优秀的特征、增加计算成本等),这种数据稀疏性的问题严重地阻碍当前多领域 DST 的发展(S. Zhu et al. 2020)。因此很有必要探索一种对话历史的全新表示方式,它应该同时拥有简练以及富含历史信息的特点。
如果对 DST 任务有所了解,自然而然地可以想到对话状态就是一个清晰、紧凑且富含信息的抽象表征(Zeng and Nie 2020)。目前已经有一些工作(Kim et al. 2020; S. Zhu et al. 2020; Zeng and Nie 2020)将前一轮的对话状态视为对话历史,他们大多将对话状态表示为序列的形式,然后将其拼接至序列的头部或者末尾。不过由于对话状态由所有槽值对组成,将其转换成序列之后会得到一段相对较长的字符串,例如 120 个字符。上述的做法无疑会增加输入序列的长度,也会成为模型提取特征的负担。在科研领域,目前对此种弊端没有过多的研究。
如何使用对话历史
- Sharp Nearby, Fuzzy Far Away How Neural Language Models Use Context
如何提取对话状态的特征
(S. Zhu et al. 2020)
(Zeng and Nie 2020) 认为使用基于 self-attention 的方法建立字符与字符之间的联系,会促成不合理的连接,导致后期的错误推理。为此,他们使用图结构对对话状态进行表示,提出了对话状态图(dialog state graph),并使用 relational-GCN 对其编码,然后将其融入进 Transformer。
数据集
RiSAWOZ数据集的质量一般,他们在生成对话语句时直接引用了模式中的槽值,没有使用“正常”的表达。例如对话中老是会出现“帮我订一家价格适中的酒店”。在现实中有关“适中”的表达可太多了,甚至,句子不包含“适中”的语义,也能表达出想要价格“适中”的酒店。其他还有“商务出行”、“水乡古镇”等。
参考文献
Bocklisch, Tom, Joey Faulkner, Nick Pawlowski, and Alan Nichol. 2017. “Rasa: Open Source Language Understanding and Dialogue Management.” arXiv Preprint arXiv:1712.05181. https://arxiv.org/abs/1712.05181.
Kim, Sungdong, Sohee Yang, Gyuwan Kim, and Sang-Woo Lee. 2020. “Efficient Dialogue State Tracking by Selectively Overwriting Memory.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 567–82. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.53.
Lee, Sungjin, Qi Zhu, Ryuichi Takanobu, Zheng Zhang, Yaoqin Zhang, Xiang Li, Jinchao Li, et al. 2019. “ConvLab: Multi-Domain End-to-End Dialog System Platform.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics. https://doi.org/10.18653/v1/p19-3011.
Mehri, Shikib, and Maxine Eskenazi. 2019. “Multi-Granularity Representations of Dialog.” arXiv Preprint arXiv:1908.09890.
Mehri, Shikib, Evgeniia Razumovskaia, Tiancheng Zhao, and Maxine Eskenazi. 2019. “Pretraining Methods for Dialog Context Representation Learning.” arXiv Preprint arXiv:1906.00414.
Papangelis, Alexandros, Mahdi Namazifar, Chandra Khatri, Yi-Chia Wang, Piero Molino, and Gokhan Tur. 2020. “Plato Dialogue System: A Flexible Conversational Ai Research Platform.” arXiv Preprint arXiv:2001.06463. https://arxiv.org/pdf/2001.06463.
Sankar, Chinnadhurai, Sandeep Subramanian, Christopher Pal, Sarath Chandar, and Yoshua Bengio. 2019. “Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study.” arXiv Preprint arXiv:1906.01603.
Tang, Gongbo, Mathias Müller, Annette Rios, and Rico Sennrich. 2018. “Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures.” arXiv Preprint arXiv:1808.08946.
Tran, Ke, Arianna Bisazza, and Christof Monz. 2018. “The Importance of Being Recurrent for Modeling Hierarchical Structure.” arXiv Preprint arXiv:1803.03585.
Ultes, Stefan, Lina M. Rojas-Barahona, Pei-Hao Su, David Vandyke, Dongho Kim, Iñigo Casanueva, Pawel Budzianowski, et al. 2017. “PyDial: A Multi-Domain Statistical Dialogue System Toolkit.” In Proceedings of ACL 2017, System Demonstrations, 73–78. Vancouver, Canada: Association for Computational Linguistics. https://www.aclweb.org/anthology/P17-4013.
Wu, Chien-Sheng, Steven Hoi, Richard Socher, and Caiming Xiong. 2020. “Tod-Bert: Pre-Trained Natural Language Understanding for Task-Oriented Dialogues.” arXiv Preprint arXiv:2004.06871.
Zeng, Yan, and Jian-Yun Nie. 2020. “Multi-Domain Dialogue State Tracking Based on State Graph.” arXiv Preprint arXiv:2010.11137.
Zhang, Zheng, Ryuichi Takanobu, Qi Zhu, Minlie Huang, and Xiaoyan Zhu. 2020. “Recent Advances and Challenges in Task-Oriented Dialog Systems.” Science China Technological Sciences. Springer, 1–17.
Zhu, Qi, Zheng Zhang, Yan Fang, Xiang Li, Ryuichi Takanobu, Jinchao Li, Baolin Peng, Jianfeng Gao, Xiaoyan Zhu, and Minlie Huang. 2020. “ConvLab-2: An Open-Source Toolkit for Building, Evaluating, and Diagnosing Dialogue Systems.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-demos.19.
Zhu, Su, Jieyu Li, Lu Chen, and Kai Yu. 2020. “Efficient Context and Schema Fusion Networks for Multi-Domain Dialogue State Tracking.” In Findings of the Association for Computational Linguistics: EMNLP 2020, 766–81. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.findings-emnlp.68.
