本文记录 2020 年开始至今的 DST 论文笔记。
突然发现有人看这篇文章,这只是本人的论文笔记,对于任务完成型对话系统论文调研的文章,可以移驾:
Slot Self-Attentive Dialogue State Tracking
现有工作的缺陷:虽然目前有部分模型考虑了槽位之间的关联,但是它们依靠大量的人力以及先验知识(恕我直言,没看出来需要人力)。此外,它们都仅利用了槽位名称的语义,忽略了槽值的共现信息。
研究目的:进一步加强槽位之间的关联。
研究目标/贡献:使用堆叠槽位自注意力(stacked slot self-attention module)学习槽位之间的相关性。
研究方法:1)在分析槽位之间的交互信息之后发现,某些槽位确实包含很强的关联,甚至在不同的领域中也存在,例如“taxi-destination”和“restaurant-food”。这验证了他们的动机,有必要同时考虑槽位名称和其对应槽值。2)slot-token attention 获取槽位表征。3)stacked slot self-attention 获取槽位关联。4)slot value matching 预测槽值。
模型架构 将 BERT 作为上下文编码器,可以得到上下文表征 \(H_t\)。虽然原文中描述了一些细节,例如只保留 512 个单词,此外由于这种做法会丢失信息,还在对话历史中加入了 non-none dialog state,但是思想比较简单,因此还是略。
将 BERT 作为槽位和槽值表征的编码器,分别可以得到槽位表征 \(h^{S_j}_{[CLS]}\) 和槽值表征 \(h^{V^t_j}_{[CLS]}\)。从中可以看出他们应该打算使用槽值匹配的方式填充槽位。由于思想比较简单,因此略。
Slot-Token Attention
使用 slot-token attention 机制获取基于上下文的槽位表征 \(c^t_{S_j}\),主要就是借助了 multi-attention 机制。公式为:
\[ \begin{aligned} r^t_{S_j} & = MultiHead(h^{S_j}_{[CLS]}, h_t, h_t) \\ c^t_{S_j} & = W^r_2 ReLU(W^r_1 Concat(h^{S_j}_{[CLS]}, r^t_{S_j}) + b^r_1) + b^r_2 \end{aligned} \]
Slot Self-Attention
使 \(C_t = [c^t_{S_1}, c^t_{S_2}, \cdots, c^t_{S_J}]\) 表示所有槽位的上下文表征,其中 \(c^t_{S_j}\) 通过 slot-token attention 计算得到,\(t\) 代表轮数。使 \(F^1_t = C_t\),那么
\[ \begin{aligned} \tilde{F}^l_t = & LayerNorm(F^l_t) \\ G^l_t = & MultiHead(\tilde{F}^l_t, \tilde{F}^l_t, \tilde{F}^l_t) + \tilde{F}^l_t \\ \tilde{G}^l_t = & LayerNorm(G^l_t) \\ F^{l+1}_t = & FFN(\tilde{G}^l_t) + \tilde{G}^l_t \end{aligned} \]
\(F^{l+1}_t = [f^t_{S_1}, f^t_{S_2}, \cdots, f^t_{S_J}]\) 为最终的组合槽位表征。由于 BERT 的输出被 normalized,因此将 \(f^t_{S_j}\) 也归一化为 \(\mathcal{r}^t_{S_j} = LayerNorm(Linear(f^t_{S_j}))\)。
Slot Value Matching
计算槽位表征和槽值表征之间的 L2 距离,在通过 softmax 之后,使用负对数似然函数优化。
Slot Attention with Value Normalization for Multi-domain Dialogue State Tracking
现有工作的缺陷:1)传统 DST 很依赖预定义的本体,为了解决这一缺陷,今年也有人提出生成式方法和 span-baed 方法。2)由于描述的多样性,DST 需要的槽值无法在语句中找到。DS-DST 提出了使用双重策略实现 DST 获得了不错的效果,说明 ontology 的重要性。3)多领域携带大量槽位(MultiWOZ2.0- 有 30 多个槽位),因此 DST 需要更高效地填充槽位。
研究目的:1)优化槽位决定的结构(博主注:这个槽位决定,可能指的是槽位填充,或者可以直接理解为 DST);2)灵活地使用本体,而不是舍弃它。
研究目标/贡献:1)提出了 Slot Attention(SA),它可以共享槽位和语句之间的知识。2)考虑到在实际场景下本体中可能的槽值数量会很大,提出了 Value Normalization(VN),其被设计为一个简单、灵活且高效的模型,在 V100 GPU 上只需要训练 8 分钟。3)为 MultiWOZ2.1 补充了 span label。4)使用不完整的本体全面地评估了 VN,结果显示只要本体的完整性大于 80%,VN 就可以获得积极的表现。
Slot Attention
SA 使用 BERT 编码最近的 \(t\) 轮对话,使用 BERT 的 Embedding 编码槽位序列,分别可以得到上下文表征 \(H^u_t\) 和槽位表征 \(H^s_t\)。值得注意的是,他们在输入序列的最前面拼接了一些固定的候选值,例如 yes, no,这主要是为了使模型能够生成特殊的单词。
Slot Gate Classification
定义 slot gate 为三元分类,预测 \(\{none, dontcare, span\}\)。使用了 Transformer 的“Scaled Dot-Product Attention”提取语句与槽位之间的知识。工作流程与大部分论文的 slot gate 类似,就不赘述了。
Span-Based Value Prediction
span 的预测只是简单地将上下文表征和槽位表征点乘,从而获得起止索引在输入序列上的概率分布。
Value Normalization
首先使用一个 gate,判断到底输出 span 还是 value in ontology。如果输出 value in ontology,就计算 span 和 value in ontology 之间的内积(均使用 [CLS] 的输出),得到 value 的概率分布。
STN4DST: A Scalable Dialogue State Tracking based on Slot Tagging Navigation
现有工作的缺陷:
Multi-Domain Dialogue State Tracking based on State Graph
现有工作的缺陷:1)以往工作只是简单地将前一轮的对话状态和当前语句拼接起来,然后使用 self-attention 建立它们的关联。但是 attention 机制也许会关注到一些不合理(spurious)的连接,导致进行错误的推理。2)CSFN-DST 与该文工作类似,但是它只考虑了一个边(edge)类型以及三个结点类型——领域(domain)、槽位(slot)、域槽对(domain, slot)。
研究目的:处理对话状态中元素的共现信息以及人类对话中过渡联系(transition relation)。作者没细说过渡是什么意思,我认为是在对话过程中不同领域之间的切换。
研究目标/贡献:1)提出 dialog state graph;2)处理多关系图中有许多相异槽值的问题。
研究方法:1)图中领域和槽值相连,边为槽位。此外如果两个领域同时出现在对话状态中,则创建一条共现边(co-occurrence edge)以此连接二者。2)使用 relational-GCN 编码对话状态图。3)仅当域槽对有值填充时才被包括在图中。4)图中几乎所有槽值用“placeholder”填充。
总结:1)CSFN-DST 只是构建了普通的边,其代表领域和槽位之间的关联,而 Grapha-DST 的边特指槽位。2)经过消融实验验证了,状态图确实可以为基于 self-attention 的隐式图(implicit graph)提供补充信息。3)该文的做法比之 CSFN-DST 确实要先进不少,从表面上看二者是在做相同的工作,但是我认为实际上 CSFN-DST 编码的是协议图,而 Graph-DST 编码的是图结构的对话状态。4)这样构建图,是否做了太多的约束?导致数据处理困难?
模型架构 将 Transformer 最后几层的 Block 改为 graph-enhanced Transformer(该文实验中为最后一层)。其运算流程为(如图右侧所示):将前一层的输出作为当前层 multi-head self-attention 的输入进而得到上下文输出,此时使用捕获的 [SLOT] 特征填充槽值,然后使用 relational-GCN 更新结点表征,并且将更新后的表征与 [slot] 融合,最后再继续执行 Transformer block 的其余流程。通过上述算法将 relational-GCN 融入 Transformer 中。需要注意的是,输入中也包含了对话状态,它们以串联的形式连接,其主要实现对话状态和当前语句的交互,而对话状态图主要捕获模式之间的联系。二者的作用不同。 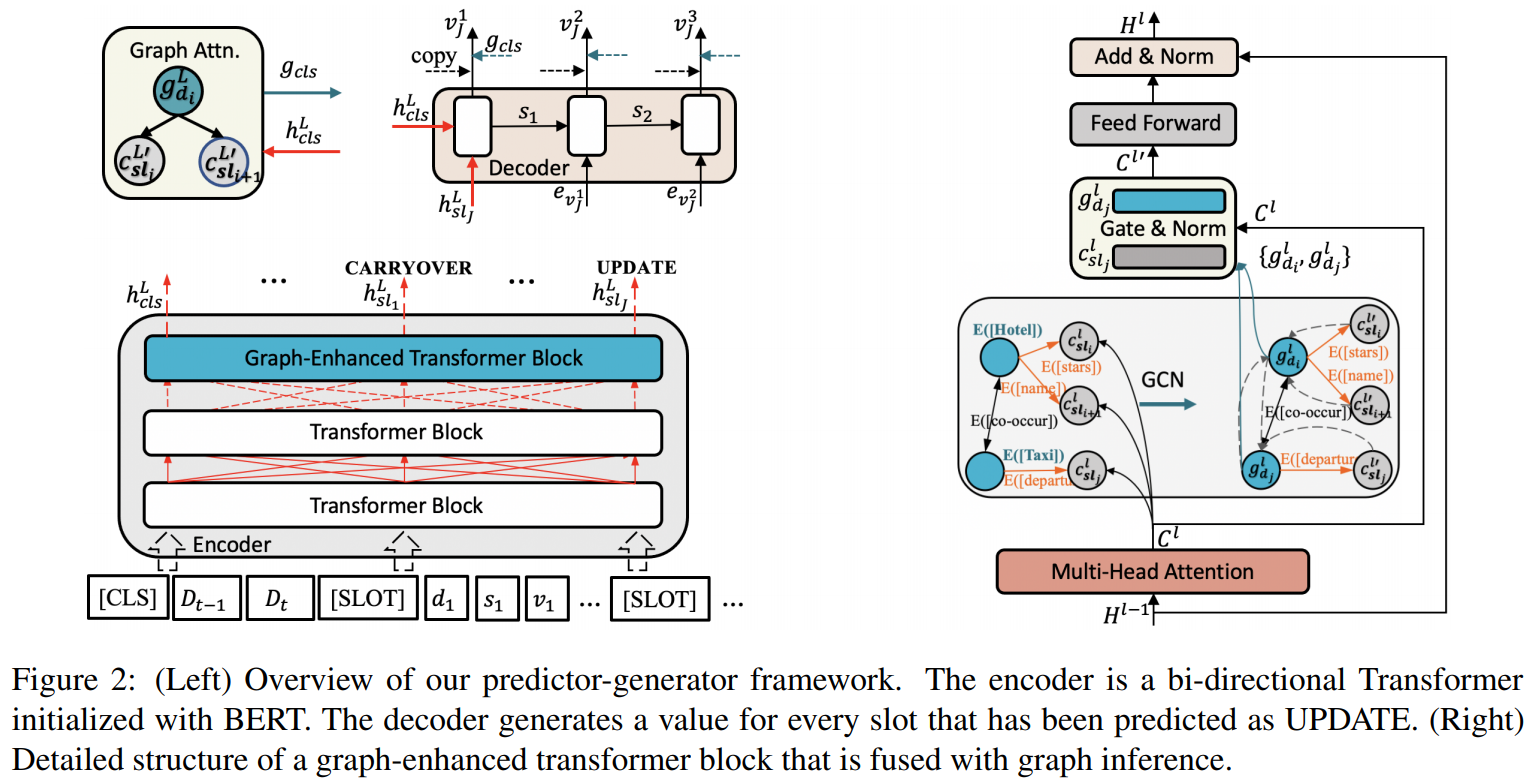
经过对 DST 中 open-vocabulary 分类的调研,发现现存的方法通常将前一轮的对话状态和对话历史拼接在一起,然后将其作为 BiTransformer 的输入。模型依靠 Transformer 的 self-attention 机制将对话状态和语句中的符号连接起来。但是 attention 机制也许会关注到一些不合理的连接,导致后续错误的推理。
本文提出构造一个对话状态图(dialog state graph),其中,来自上一轮对话状态中的领域(domain)、槽位(slot)以及槽值(value)被恰当地连接起来。如图 1 所示。使用 relational-GCN(关系图卷积网络)对其编码,它被融合进 Transformer 中。
可以将基于双向 self-attention 的方法视为图神经网络,其输入为每个字符都相连的图,无论它们在对话历史还是对话状态中,都可以通过 attention 被连接。这种图结构对 DST 很有帮助。例如,给定酒店“名称”和出租车“出发地”的图,attention 可以建立它们之间的关联,这意味着我们可以推断出出租车的出发地和酒店名称相同。然而 Transformer 所使用的图通常拥有大量结点,attention 可能会连接两个与对话无关的结点,从而导致错误推理。
图需要同时表现对话历史中的关键实体和强连接(strong connection)。强连接不仅依赖于对话历史,还需要引导对话。例如,用户预订火车的时候,通常还会预订酒店,前者通常自然地会影响后者(自然过渡,natural transition)。因此应该在图中创建强连接。这种自然过渡在以往的研究常常被忽略。
在构建图时,除了必要的结点(node)和边(edge),还创建了一种特殊的边。如果有两个领域同时出现在对话状态中,则创建一种共现边(co-occurrence edge)以此连接二者。
为了有效地利用该图,需要解决以下两个问题:
- 为了聚合多关系图的结点信息,使用了 relational-GCN。
- 对于将所有槽值表现在图中,是不切实际的(因为太多且有些没有被预定义)。为此,图中的槽值结点均被定义为一个占位符,并且不为它们创建嵌入,而是使用对应 Transformer 的隐藏状态输出,即 \([SLOT]\) 位置。最终,将这种基于图的推理与常用的 Transformer encoder 融合了起来。
以下将首先定义模型的形式表示,然后介绍对话状态图的结构,最后描述如何将对话状态图融入 Transformer。
Method
定义一场 \(T\) 轮的对话为 \(\{(D_1 S_1), \cdots, (D_T, S_T)\}\),其中 \(D_t\) 代表第 \(t\) 轮的系统语句和用户语句,\(S_t\) 代表当前轮的对话状态。定义 \(S_t\) 为 \((d_j, s_j, v_j)|1 \le j \le J\),其中 \(J\) 为域槽对的总量,也就是说 \(S_t\) 记录的是所有域槽对。如果域槽对的槽值为空,则 \(v_j\) 为 \(NULL\)。
DST 的目标是给定 \(\{(D_1 S_1), \cdots, (D_{t-1}, S_{t-1}), (D_t)\}\),预测 \(S_t\)。该文采用 SOM-DST 的思想,只输入 \(D_{t-1}, D_T, S_{T-1}\)。由于该文只是关注状态图的利用,所以模型也采用 SOM-DST 的结构。下面先介绍一下 SOM-DST 的框架。
对话状态图的结构
给定 \(S_{t-1} = \{(d_j, s_j, v_j)|1 \le j \le J\}\),对于每个 \((d_j, s_j, v_j)\),使得领域结点 \(d_j\) 和槽值结点 \(v_j\)(placeholder)以槽位边(slot edge)相连。其中槽位边是单向的,共现边是双向的。每个领域结点以及槽位边都有它们对应的嵌入。
以往的工作通常假设域槽对之间是无关的。该文则编码 domain-domain,slot-slot,domain-slot 的共现关系,这可能对 DST 有所帮助。此外,由于在 MultiWOZ 中存在过多的槽值(4500),因此该文假定它们没有被预定义,图中每个槽值结点几乎都是“placeholder”占位符。它不属于图结点嵌入,这些位置将会被动态地填入对应的 self-attention 输出,即 \([SLOT]\) 位置。
Graph-enhanced Transformer
- multi-head attn 如图 2 右侧所示,第 \(l-1\) 层的输出 \(H^{t-1}=[h^{l-1}_{cls}, \cdots, h^{l-1}_{sl_J}, \cdots]\) 被输入进 multi-head self-attention layer,那么上下文表征 \(C^l=[c^l_{cls}, \cdots, c^l_{sl_J}, \cdots]\) 可以由以下公式计算得到: \[ \begin{align} C^l & = Concat(head_1, \cdots, head_h) \\ head_j & = softmax(\frac{Q_j K^T_j}{\sqrt{d_k}}) V_j \end{align} \]
- relational-GCN 将得到的 \([SLOT]\) 表征填充各槽值(而不是原有位置槽值的表征),其余结点用词向量初始化。(个人觉得有点奇怪,直接填入 placeholder 的表征不就行了?)接下来,使用relational-GCN 更新结点表征。例如,对于一个领域结点 \(d\): \[g^l_d = f(W_S(e_d - e_S) + \sum_{(v, sl) \in N(d)} W_O(c^l_v - e_{sl}) + \sum_{d' \in N(d)} (W_I + W_O)(e_{d'} - e_{co})) \]
- fusion
Dialogue State Tracking with Explicit Slot Connection Modeling
- 现有工作的缺陷:
- 研究目的:
- 研究目标/贡献:-
- 研究方法:
- 总结:

在多领域场景下,用户经常通过省略(ellipsis)、指代(reference)来表达某些其它领域槽位提到的槽值。为了解决这种现象,我们提出了 DST-SC(Dialogue State Tracking with Slot Connections)模型。
以下为博主的思考,并非翻译、阅读笔记。这是因为这篇论文的思想与 TripPy 类似,而在之前我已经阅读过 TripPy 的论文。
仔细看了一下之后发现与 TripPy 所提出机制的一部分很像,都是为了处理省略、共指而生的。区别是 DST-SC 使用的 encoder-decoder 模型,它在生成槽值时,始终使用 soft-gated copy mechanism。
具体来说,在解码时,使用一个门控 \(g_1\) 合并了对话历史的概率分布和词表概率分布,得到了 \(P_{gen}\) 概率分布。其次使用另一个门控 \(g_2\) 合并了 \(P_{gen}\) 和 \(P_{vc}\),得到了最终的概率分布 \(P\)。使用该概率分布即可解码得到当前时间步的单词。其中概率分布 \(P_{vc}\) 是从上一轮的对话状态中计算得到的。
总的来说,他们延续了 TRADE 的做法,在此基础上,又额外加了一层 soft-gated copy mechanism。
CREDIT: Coarse-to-Fine Sequence Generation for Dialogue State Tracking
提出了 CoaRsE-to-fine DIalogue state Tracking(CREDIT) 模型。以前的方法通常将对话状态定义为独立的三元组 \((domain, slot, value)\),而本文将 DST 转化为序列生成问题。 
A Contextual Hierarchical Attention Networkwith Adaptive Objective for Dialogue State Tracking
现有工作的缺陷:1)传统 DST 模型通常只使用当前轮语句决定对话状态,这忽视了对对话历史的使用(博主注:现在,2020 年中期之后,又有一些工作再一次地想要舍弃对话历史,因为这会导致模型运行速度下降)。2)没有考虑 slot imbalance 的问题。
研究目的:1)更全面地捕获对话历史中的信息;2)处理槽位不平衡为题。
研究目标/贡献:1)提出 contextual hierarchical attention network 以此全面地利用对话历史的相关信息。2)使用 state transition prediction task 进一步增强 DST。3)设计一个适应性优化目标通过动态调整每个槽位的权重,以解决 slot imbalance 的问题。
Contextual Hierarchical Attention Network
为了更好地从对话历史中获得相关上下文,设计了 Slot-Word Attention 和 Slot-Turn Attention 分别查询相关关键字和相关轮对话。
Sentence Encoder. 使用可微调 BERT 获得语句表征 \(h_t = BERT_{finetue}([R_t; U_t])\),使用固定 BERT 分别获取槽位 \(s\) 表征 \(h^s = BERT_{fixed}(s)\) 和槽值 \(v_t\) 表征 \(v_t = BERT_{fixed}(v_t)\)。值得注意的是,在获取对话历史表征时,他们没有直接拼接所有语句,而是使用 \(t\) 个可微调 BERT 以此分别独立地计算 \(t\) 轮的语句对。
Slot-Word Attention. slot-word attention 是 multi-head attention。对于每个槽位 \(s\),slot-word attention 从每轮 \(t\) 中总结 word-level slot-related 信息,并将其转化为 \(d\) 维向量 \(c^{word}_{s,t} = MultiHead(h^s, h_t, h_t)\)。
Context Encoder. context encoder 是单向 transformer encoder,被用于建立 word-level slot-related 信息之间的上下文关系,这些信息分别来自 \(\{1, \cdots, t\}\) 轮。context encoder 由 \(N\) 个相同层堆叠而成。最终可以得到 \(c^{ctx}_{s, \le t}\)。
Slot-Turn Attention. 又是一个 multi-head attention,将 \(h^s\) 和 \(c^{ctx}_{s, \le t}\) 作为输入,略。
Global-Local Fusion Gate. 将来自 Slot-Word Attention 和 Slot-Turn Attention 的最后一轮信息动态地组合成 \(c^{gate}_{s,t}\),在归一化后得到 \(o_{s,t}\)。
最后使用 L2 norm 计算 \(o_{s,t}\) 和 \(h^v_t\) 之间的距离,判断是否将槽值 \(v_t\) 填充槽位 \(s\)。(博主注:为什么不直接做多元分类呢?)
State Transition Prediction
为了更好地捕获相关上下文,进一步提出了辅助的二元分类任务,与 DST 联合训练,即 State Transition Prediction(STP),它预测当前槽值相较于前一轮是否被更新。
Adaptive Objective
略。
SAS: Dialogue State Tracking via Slot Attention and Slot Information Sharing
现有工作的缺陷:由于对话历史中包含复杂且过量的信息,现有模型很难处理这些长距离交互上下文。
研究目的:1)减少上下文中多余信息的干扰;2)改进长对话上下文追踪。
研究目标/贡献:1)提出 Slot Attention 以此从原始对话中学习一组特定槽位的特征;2)提出 Slot Information Sharing 以此整合上述的特征。
模型架构 上下文编码器使用的是 BiGRU,没什么好讲的,略。
Slot Attention
在一场对话中,用户可能会请求多项服务,例如订餐、观光、打车。当用户所提及的信息相似时,模型提取出的信息可能对预测有害,例如餐厅和出租车都提到了时间(time)和预定人数(people)。为了分离嘈杂的对话历史中的关键特征,构建了 slot attention。(博主注:引起这一问题主要是因为对话历史过长,导致用户表达的信息被模型错误使用。然而,目前有部分模型逐渐舍弃了对话历史,只将当前轮对话输入模型。这避免了上述问题,同时还能取得不错的表现)
slot attention 能够仅从历史信息中为每个槽位提取出有用的信息。其工作流程主要为:1)首先使用 GRU 获取槽位的表征,主要是简单地将槽位的序列输入 GRU,取最后一个时间步的输出 \(sh^{enc}_{j_{|N|}}\) 作为槽位 \(s_j\) 的表征,\(|N|\) 为槽位序列的长度。2)然后通过槽位信息 \(sh^{enc}_{j_{|N|}}\) 和对话历史 \(H_t=[h^{enc}_1, \cdots, h^{enc}_{|X_t|}]\) 之间的注意力交互,从而获得上下文向量 \(c_j\):
\[ \begin{aligned} a^j = & (H_t)^T sh^{enc}_{j_{|N|}} \\ sc^j_i = & \frac{exp(a^j_i)}{\sum^{|X_t|}_{i=1} exp(a^j_i)} \\ c_j = & \sum^{|X_t|}_{i=1} sc^j_i h^{enc}_i \end{aligned} \]
那么上下文向量 \(c_j\) 就包含着从对话历史中攫取出来的特定槽位信息。最后可以类似地获得 \(J\) 个槽位的上下文向量 \(c=[c_1, \cdots, c_J]\)。
Slot Information Sharing
使用槽位相似度矩阵(slot similarity matrix)实现槽位信息共享,其维度为 \(J \times J\)。作者探索了两种创建矩阵的方式,分别为 fix combination sharing 和 k-means sharing,前者利用了余弦相似度,后者利用了 k-means 算法。创建思想较为简单,就不赘述了。
在得到槽位相似度矩阵 \(M\) 之后,我们可以通过以下方式得到槽位聚合向量 \(int = [int_i, \cdots, int_J]\):
\[int_j = \sum^J_{i=1} c_i \cdot M_{ij}, M_{ij} \in {0, 1} \]
说白了就是一个矩阵相乘的操作,这个操作聚合了相关槽位的特征。(博主注:感觉思想较为简单,但是有启发意义。)
解码步骤略,应该与 TRADE 类似。
Efficient Context and Schema Fusion Networks for Multi-Domain Dialogue State Tracking
现有工作的缺陷:由于域槽对数量以及对话长度的增加,数据稀疏性(data sparsity)的问题成了多领域 DST 的主要障碍。
研究目的:1)缓解数据稀疏性的问题;2)考虑不同域槽对之间的关联(算是对 schema 进行了初步的编码)。
研究目标/贡献:1)使用前一轮对话状态表示对话历史;2)提出模式图,并对其编码。
研究方法:1)提出了 Schema Graph 并实现了一个基本模型 context and schema fusion networks (CSFN-DST),其主要修改了 Transformer 的 Multi-head Attention 机制。具体只是使用一个邻接矩阵实现。
总结:1)可以将 CSFN-DST 视为一种全新的域槽对表示方式,不过我觉得这好像没有利用到知识图谱的优势。此外虽然作者列出了 Graph Neural Network 的相关工作,但是并没有使用 GNN 去提取特征。2)虽然最后他们讨论了在输入中是否需要更多上下文信息的问题,但是他们在消融实验中只是额外加入上一轮的对话语句。个人认为这个实验不足以证明论文中提到的观点,即只使用当前轮的系统语句、用户语句和上一轮的对话状态是有效的。这是因为上下文信息太少了,起码再多加几轮,然后做一个对比。3)该文作者与我的想法类似,也认为 dontcare 这个槽位是比较有挑战的子任务。
模型结构 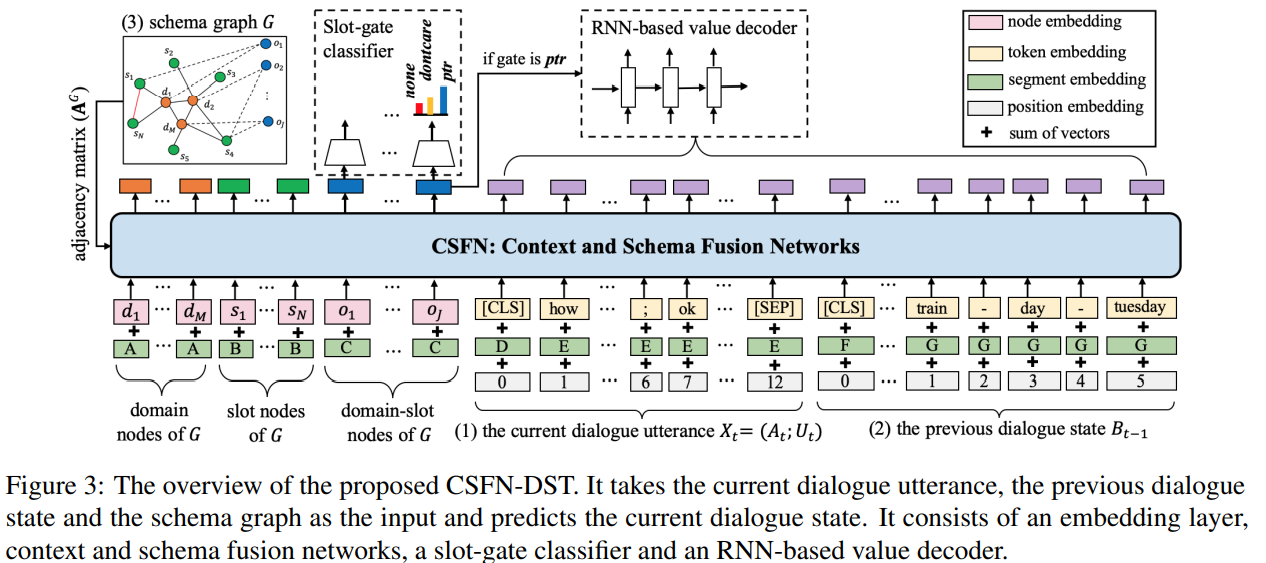
在多领域 DST 中,由于候选状态数量以及对话长度的增加,数据稀疏性的问题成了一个主要的障碍。为了高效地编码对话上下文,我们使用了前一轮预测出的对话状态以及当前轮的对话语句作为 DST 的输入。(博主注:数据的稀疏性指的是候选状态过多但是大部分是无意义的;对话长度增加但是大部分语句也是无意义的。为了处理这一问题,该文打算使用上一轮的对话状态近似对话上下文)
此外为了考虑不同域槽对之间的关联,还开发了包含先验知识的协议图(schema graph)。
本文提出了一个新颖的上下文与协议融合的网络(context and schema fusion network)。
CSFN-DST 使用系统回复 \(A_t\),用户语句 \(U_t\) 以及前一轮的对话状态 \(B_{t-1}\) 作为模型的输入。在训练阶段,直接使用真实值 \(B_{t-1}\),但是在推理阶段,使用预测出的对话状态。
Schema Graph:为了将不同域槽对之间的联系考虑进去,并且将它们作为一种额外的输入以此引导上下文编码,我们将它们表示为 schema graph(协议图谱) \(G=(V, E)\),\(V\) 代表结点(node),\(E\) 代表边(edge)。如下图所示。协议图中一共有领域、槽位以及域槽对三种结点,以及在不同结点之间的四种类型无向边。 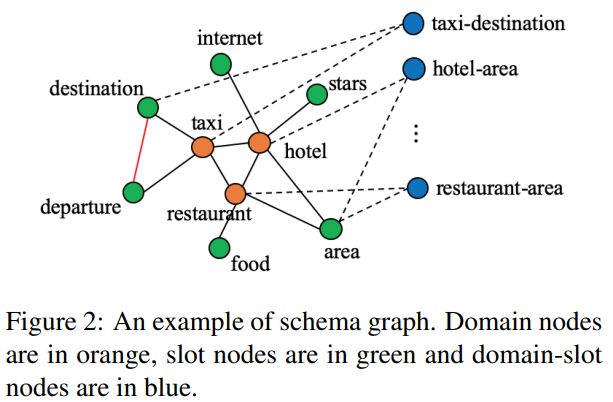
输入嵌入
Dialogue Utterance \(X = [CLS] \oplus A_t \oplus ; \oplus U_t \oplus [SEP]\),输入嵌入由词向量,片段嵌入(segment embedding)以及位置嵌入组成。
Previous Dialogue State 用上一轮的对话状态来表示历史对话,表示为 \(B_{t-1} = [CLS] \oplus R^1_{t-1} \oplus \cdots \oplus R^K_{t-1}\),其中 \(K\) 为 \(B_{t-1}\) 中的三元组数量。每个三元组都被表示为一个序列,即 \(R = d \oplus - \oplus s \oplus - \oplus v\)。其中,所有的符号都会被表示为单词,例如 pricereange -> price range,dontcare -> dont care。
Schema Graph 所有的结点按如下形式排列:\(G = d_1 \oplus \cdots \oplus d_M \oplus s_1 \oplus \cdots \oplus s_N \oplus o_1 \oplus \cdots \oplus o_J\)。每一个结点嵌入都由对应的 domain/slot/domain-slot 词向量初始化,图谱中的位置编码被省略。图谱中的边被表示为邻接矩阵 \(A^G\),其中要么为 1 要么为 0。为了强调不同类型结点的边在计算时是不一样的,我们利用结点类型得到了片段嵌入。
Context and Schema Fusion Network
Graph-based Multi-head Attention 对 Transformer 进行了改造。在执行 Multi-head Attention 时,额外使用邻接矩阵 \(A^G \in \mathbb{R}^{|Y| \times |Z|}\) 作为 mask。
Context- and Schema-Aware Encoding CSFN 与 Transformer 类似,也是由多层的神经网络组成的,每层的输出都是下一层的输入。具体可以公式化为:
\[ \begin{align} I_{GG} & = GraphMultiHead_{\Theta_{GG}}(H^G_i, H^G_i, A^G) \\ E_{GX} & = MultiHead_{\Theta_{GX}}(H^G_i, H^{X_t}_i) \\ E_{GB} & = MultiHead_{\Theta_{GB}}(H^G_i, H^{B_{t-1}}_i) \\ C_G & = LayerNorm(H^G_i + I_{GG} + E_{GX} + E_{GB}) \\ H^G_{i+1} & = LayerNorm(C_G + FFN(C_G)) \end{align} \]
其中 \(FFN\) 代表两层全连接层以及在它们之间的一个 ReLU 激活函数。即 \(FFN(x) = max(0, xW_1 + b_1)W_2 + b_2\)。
类似地,可以计算出 \(H^{X_t}_i, H^{B_{t-1}}_i\)。不过有一点需要注意,Graph-based Multi-head Attention 并不是总是会被使用,详见原论文的 Appendix A。
State Prediction
与 TRADE 一样,将槽位类型分类 \(\{none, dontcare, ptr\}\)。其中由于协议图中包含了域槽对,所以只需要在 CSFN 中取出所有域槽对的表征即可,进一步预测槽位的类别,即模型架构图中的深蓝色部分。
如果槽位类型为 \(ptr\) 则使用 soft-based copy mechanism 生成槽值。
使用BERT
如果使用 BERT 初始化词向量以及 CSFN 的所有参数,会提升大约 2 个百分点。
结果分析
5.5.1 节中讨论了是否需要更多的上下文,并且做了实验。在额外增加上一轮的语句 \(X_{t-1}\) 之后,得到了略差的准确率,所以得出结论:只编码当前的语句以及上一轮的对话状态会更高效。
Efficient Dialogue State Tracking by Selectively Overwriting Memory
现有工作的缺陷:1)传统 fixed-vocabulary DST 方法需要完整的本体,首先通常很难预先获取本体,其次无法处理未知槽值的问题,最后这种方法无法扩展到大规模的本体上。2)为了解决上述问题,最近有研究专注于 open-vocabulary DST 方法,虽然相对灵活且有能力处理未知槽值问题,但是大多数的方法需要在每一轮从头预测对话状态,这不够高效。
研究目的:好像没有说的很明白。
研究目标/贡献:1)借助上一轮的对话状态,现在模型只需要预测当前轮的子集槽位即可,不需要从头开始预测对话状态。2)提出了状态操作预测。
模型结构 首先,在每轮 \(t\),state operation predictor 都会选择一个状态操作 \(r^j_t \in \mathcal{O} = \{CARRYOVER, DELETE, DONTCARE, UPDATE\}\),然后为每个槽位 \(S^j\) 填充其对应的槽值 \(V^j_t\)。当以上流程执行时,槽值要么保持不变(CARRYOVER),要么做出改变(DELETE, DONTCARE, UPDATE):
\[ V^j_t = \begin{cases} V^j_{t-1} & \text{if} \, r^j_t = CARRYOVER \\ NULL & \text{if} \, r^j_t = DELETE \\ DONTCARE & \text{if} \, r^j_t = DONTCARE \\ v & \text{if} \, r^j_t = UPDATE \end{cases} \]
State Operation Predictor
用 BERT 编码可以得到 [CLS] 表征 \(h^{[CLS]}_t\) 和第 \(j\) 个 [SLOT] 表征 \(h^{[SLOT]^j}_t\)。通过带有可学习权重 \(W_{pool}\) 的前馈层我们可以得到聚合序列信息的表征 \(h^X_t = tanh(W_{pool} h^{[CLS]}_t)\)。
对于每个槽位表征 \(h^{[SLOT]^j}_t\),状态操作预测是基于其的四元分类:\(P^j_{opr,t} = softmax(W_{opr} h^{[SLOT]^j}_t)\)。
当预测结果为 UPDATE 时,将会执行槽值生成。
Slot Value Generator
本文提出的 Slot Value Generator 与其他的生成器不同,它为 \(J'_t\) 个槽位生成槽值,而不是 \(J\),通常 \(J'_t \ll J\)。因此能更有效得计算。
生成步骤与 TRADE 类似,就不赘述了。一般来说,这种 generative DST,槽值生成步骤都差不多。
优化函数
比较简单,具体就不介绍了。但是有一点需要指出,他们将领域预测任务作为额外的任务,期望能够使模型学习到槽位操作与领域转换之间的关联。
