本文总结:
- 观点:通用的预训练模型对任务导向的对话任务没什么帮助,故研发了 TOD-BERT
- 选择与 BERT 类似的架构预训练 TOD-BERT,即 BERT-base uncased model(12L 12A 768H)
- 在 byte-pair embeddings 加入了两个特殊符号:\([USR], [SYS]\)
- 使用 MLM loss 和 RCL 两个函数训练模型
- MLM 与 BERT 略有不同,TOD-BERT 会在训练时动态执行掩盖、替换。其他详见下面的章节
- RCL 是一个新颖的做法,详见具体章节
通用文本和任务导向对话之间语言模式的根本差异,导致了现存的预训练语言模型实际上没什么用。本文为语言模型统一了九种人人交互以及多轮的任务导向对话数据集。
为了在预训练阶段更好地对对话行为进行建模,我们在 MLM(Masked Language Modeling)中引入了“用户”和“系统”符号。
预训练所使用的数据集以及建模方法
本文的目的是证明以下的假设:对于任务导向的下游任务而言,使用任务导向语料预训练得到的自监督语言模型可以比现存的预训练模型学到更好的表征。并且需要强调的是:我们最关心的不是 1)我们的预训练模型能否在每个下游任务上得到 SOTA 结果,这是因为目前最好的模型都是建立在预训练模型上(博主注:这些模型可能借助了预训练模型的威力)。2)我们的模型能否简单地替代它们。
我们收集并整合了九种人人交互以及多轮的任务导向对话语料,以此训练任务导向对话 BERT(Task-oriented Dialog BERT,TOD-BERT)。
与 BERT 类似的是:我们将 TOD-BERT 定义为 MLM 并且使用 deep bidirectional Transformer 编码器。与 BERT 不同的是:TOD-BERT 为用户和系统引入了两个特殊符号,以此对对应的对话行为建模。在预训练阶段,结合回复选择任务中的 contrastive objective function 捕获回复的相似性。
九种语料分别为: 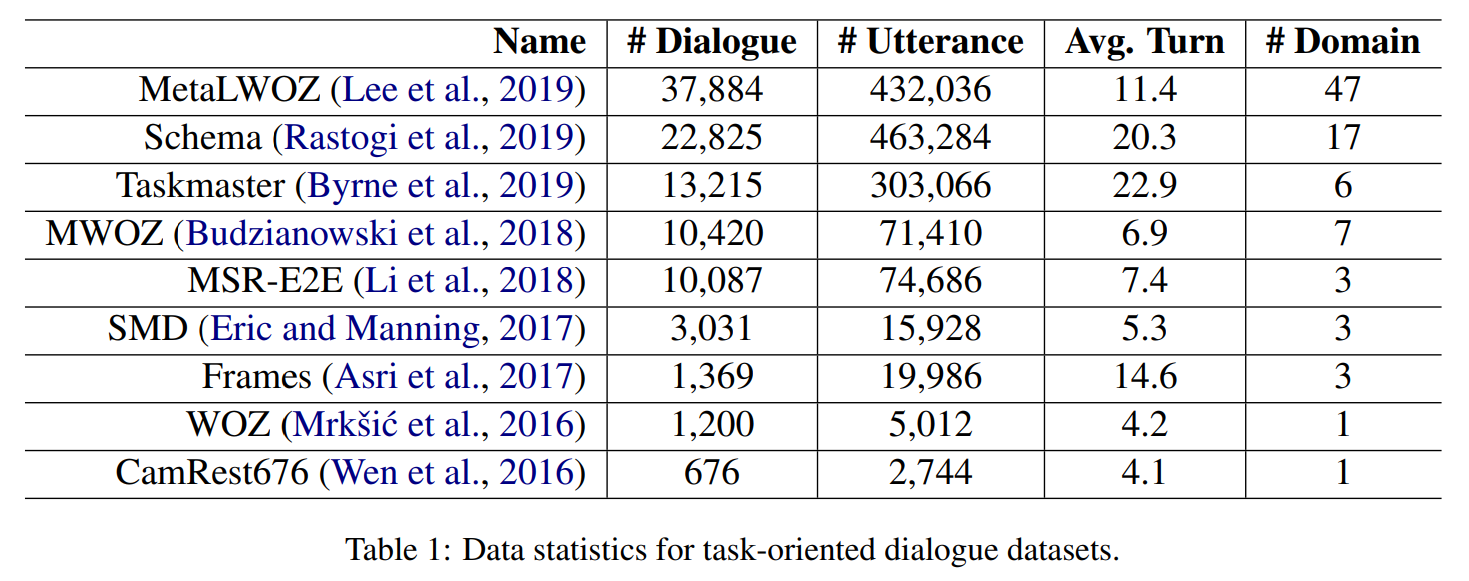
TOD-BERT
我们基于 BERT 的架构使用两种损失函数训练 TOD-BERT,分别为:掩码语言模型(Masked Language Model,MLM)loss 和回复对比损失(response contrastive loss,RCL)。值得注意的是,我们所使用的数据集也可以预训练其他任意的预训练模型结构。而我们选择 BERT 是因为,它是近年来在 NLP 研究中被广泛使用的模型。我们使用了 BERT-base uncased model,拥有 12 层和 12 个注意力头架构,以及 768 个隐藏状态。
为了捕获发言者的信息以及语句中潜在的交互行为,我们在 byte-pair embeddings(Mrkšić et al. 2017)中增加了两个特殊符号:\([USR], [SYS]\)。我们将二者加在每一句话的前面,然后将所有语句拼接成一句话。
例如有 \(D=\{S_1, U_1, \cdots, S_N, U_N\}\),那么输入就可以被处理为“\([SYS] S_1 [USR] U_1 \cdots\)”。
MLM
MLM 是类 BERT 架构的通用预训练策略,它随机采样输入序列,并将被选择到的字符替换为特殊符号 \([MASK]\)。MLM loss 函数是预测被掩盖符号的交叉熵函数。在原始的实现中,随机掩盖以及替换只在开始被执行一次,并在训练期间一直保持。然而,我们在进行批训练时动态地执行符号掩盖。TOD-BERT 直接被 BERT(一组不错的初始参数)初始化,然后进一步地在那些任务导向语料上进行微调。MLM loss 函数为:
\[ L_{mlm} = - \sum^M_{m=1} \log P(x_m) \]
其中 M 是被掩盖字符的数量。\(P(x_m)\) 是符号 \(x_m\) 在整个词表大小上被预测出的概率。
Response contrastive loss
RCL 可以被用于对话语言建模上,这是因为它不需要任何额外的人工标注。使用 RCL 预训练有一系列的优势:1)可以学到 \([CLS]\) 更好的表征;2)鼓励模型捕捉潜在的对话顺序、结构信息以及回复相似度。
与原本的 NSP 优化目标不同,我们应用了 dual-encoder 方法并且模拟了多重负采样。
- 首先,取出一个批次的对话 \(\{D_1, \cdots, D_b\}\),然后随机选择第 t 轮切分对话。例如,\(D_1\) 可以被切为两部分,上下文 \(\{S^1_1, U^1_1, \cdots, S^1_t, U^1_t\}\) 和回复 \(\{S^1_{t+1}\}\)。
- 使用 TOD-BERT 编码所有语句,得到上下文矩阵 \(C \in \mathbb{R}^{b \times d_B}\) 以及回复矩阵 \(R \in \mathbb{R}^{b \times d_B}\),其中向量来自[CLS]位置的隐藏状态,\(b, d_B\)分别代表批次大小以及隐藏状态维度。TOD-BERT将来自同一批次的其他回复视作被随机选择的负样本。那么 RCL 目标函数为: \[ \begin{align} L_{\text{rcl}} & = - \sum^b_{i=1} log M_{i,i} \\ M & = \text{softmax}(CR^T) \in \mathbb{R}^{b \times b} \end{align} \]
- 增加批次大小到一个量级,会在下游任务上获得更好的性能,尤其是对于回复选择。批次大小是一个超参数,由于可能会受限于硬件,我们还尝试了其他采样策略,但是没有看到明显的提升。
总览
预训练损失函数是 \(L_{\text{mlm}}\) 和 \(L_{\text{rcl}}\) 的加权和,在我们的试验里,只是简单地相加。
我们没有使用 warm-up 直接逐渐减少学习率。
我们使用 AdamW 并且在所有层以及注意力的权重上加上 0.1 dropout。
使用了 GELU。
下游任务
在本文中,我们关心的是与 BERT 相比,使用 TOD-BERT 是否能够展示出任意的优势。所以在下游任务上微调时,我们避免在结构的顶层加上过多的额外组件。并且为了公平起见,我们使用同样的结构以及类似的参数量。
我们选择了几项重要的任务导向下游任务用于评估,分别为:intent recognition, dialogue state tracking, dialogue act prediction, and response selection。
以下只介绍对话状态追踪
Dialogue state tracking
此节不做翻译,以下为博主的理解。
TOD-BERT 所使用的对话状态追踪算法应该属于 NBT 那类,让第 \(j\) 个槽位的所有槽值与用户语句进行一一判别,以此判断该槽位的槽值有没有被用户提及。他们没有用到近几年提出的 span 方法。
那么生成第 \(j\) 个槽位的第 \(i\) 个槽值的概率的公式为:
\[ S^j_i = Sim(G_j(F(X)), F(v^j_i)) \in \mathbb{R}^1 \]
其中 \(Sim\) 代表余弦相似度函数,\(G_j\) 代表第 \(j\) 个槽位的映射函数,\(F\) 代表预训练模型,\(v^j_i\) 代表第 \(j\) 个槽位的第 \(i\) 个槽值。此外,使用 \([CLS]\) 的表征作为函数 \(F\) 的输出。
参考文献
Mrkšić, Nikola, Diarmuid Ó Séaghdha, Tsung-Hsien Wen, Blaise Thomson, and Steve Young. 2017. “Neural Belief Tracker: Data-Driven Dialogue State Tracking.” In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1777–88.
