本文记录最初至 2019 年的 DST 论文笔记。本文已更新,移驾DST论文笔记(二)。
突然发现有人看这篇文章,这只是本人的论文笔记,对于任务完成型对话系统论文调研的文章,可以移驾:
TripPy: A Triple Copy Strategy for Value Independent Neural Dialog State Tracking
模型的计算方法与 DS-DST 几乎完全一致,只不过补充了几点 slot gate 的类型。
唯一不同的在特征提取这块。DS-DST 将 CLS,一个域槽对和对话上下文拼接起来。由于所有域槽对的词向量是不同的,则可以凭此遍历所有的域槽对,使得每次捕获到的特征都是根据域槽对的变化而变化。所以当使用 CLS 进行 slot gate 分类时,可以确定该 slot gate 是基于某一域槽对的,并且 CLS 表征总是不同的。但是这样的做法计算起来特别麻烦,因为如果想要向量化,必须复制 N 份上下文(N 为域槽对数量)。
TripPy 应该是略微地改进了它,它移除了输入中的域槽对,其他基本不变,顶多是改变了一下上下文的输入顺序,这并无大碍。然后,TripPy 为每一个域槽对都设计了一个线性层用于计算 slot gate。这也能使得 CLS 的表征总是不同,因为线性层中的权重矩阵是不同的。但是这样貌似更加无法向量化了?反而,弄巧成拙?
所以,我认为在 dst 模型上,还是 TRADE 模型设计的更合理,它是采用了 attention 的机制。相比于 DS-DST 和 TripPy,参数量大大地减少,并且可以向量化。

本文提出三种复制机制:1)从用户语句中直接提取出槽值的跨度预测(span prediction);2)从 system inform memory 中复制出槽值,其为系统回复操作的追踪;3)从对话状态历史中复制槽值。
令 \(X = \{(U_1, M_1), \cdots, (U_T, M_T)\}\),\(U_t\) 是 \(t\) 轮时的用户语句,\(M_t\) 是 \(t\) 轮时的回复语句。模型的任务是 1)决定每轮是否提到了 \(S = \{S_1, \cdots, S_N\}\) 中的 \(N\) 个域槽对;2)预测每个 \(S_n\) 的槽值;3)追踪整场对话过程中的对话状态。
Context Encoder
使用 BERT 提取上下文特征,公式为:
\(R_t = BERT([CLS] \oplus U_t \oplus [SEP] \oplus M_t \oplus [SEP] \oplus H_t \oplus [SEP])\)
其中 \(U_t\) 是 t 轮的用户语句,\([CLS], [SEP]\) 都是 BERT 需要的特殊符号,分别为分类特殊符和分隔符,\(H_t\) 为对话历史。那么 \(R_t = [r^{CLS}_t, r^1_t, \cdots, r^{seq_{max}}_t]\)。以上都是比较基础的公式,具体说明略。值得注意得是,TripPy 的输入是逆序的,先输入 t 轮的对话,再输入逆序的历史对话。
Slot Gates
Slot Gate 的思想应该取自 TRADE 模型,简单来说,就是设计一个多分类器,判断接下来的操作应该交给哪个组件执行,一般来说可以选择 \(\{None, dontcare, Ptr, \cdots\}\)。
TripPy 为每一个域槽对都配备了一个 slot gate。还是跟以往的做法差不多,将槽值的识别问题转换为一个分类问题。与 TRADE 模型不同的是,TripPy 的 slot gate 在每轮为槽位 \(S_n\) 进行分类,类别包括 \(C = \{none, dontcare, span, inform, refer\}\),其中 inform 代表系统的通知,refer 代表历史对话状态中所提到的,其他都是类似的,就不提了。
由于在 Context Encoder 中已经提取到了上下文特征,而且这步也是 BERT 做的,所以 Slot Gate 实际上就是做几个线性分类而已。BERT 可以得到 \(r^{CLS}_t\),这代表 \(t\) 轮 \([CLS]\) 的表征,那么域槽对 \(S_n\) 在类别 \(C\) 上的概率分布为:
\[p^{gate}_{t,s}(r^{CLS}_t) = softmax(W^{gate}_s \cdot r^{CLS}_t + b^{gate}_s) \in \mathbb{R}^5 \]
需要注意的是,上述的分类器是对一个域槽对进行五元分类。但是在系统中我们拥有 \(N\) 个域槽对,所以我们需要 \(N\) 个上述的分类器,这就导致需要一定的参数量。
对于特殊的槽位 Boolean Slot,也使用了类似的方法,但是类别 \(C_{bool} = \{none, dontcare, true, false\}\)。
Span-based Value Prediction
使用 Ptr 神经网络预测槽值在用户语句中的位置,包括 start 以及 end 位置。如果 end > start,则简单地将跨度(span)置为空。
System Inform Memory for Value Prediction
系统通知记忆(System Inform Memory) \(I_t = \{I^1_t, \cdots, I^N_t\}\) 追踪系统提到的所有槽值对。简单来说,这就是一个 python 中的 dict,记录每一个槽值对是否被系统提及到。简单来说,如果用户提到了某个系统所通知给用户的槽值,那么槽位应该直接填充这个“通知值”,而不是去使用 Ptr 预测跨度,然后从用户的语句中提取出来。
这听起来可能有点奇怪,因为如果用户提到了某个系统的“通知值”,那么理所当然地我们也可以使用 Ptr 从用于语句中提取出来,为什么要多此一举使用 System Inform Memory 呢?原因在于,用户所提到的“通知值”可能并不是其本身。思考下面的例句,“系统:‘xx酒店有你想要的食物类型。’;用户:‘好的,就是它了。’”。可见系统提到的“xx酒店”,用户并没有直接引用它,而是使用了一种共指的语法。
DS Memory for Coreference Resolution
更复杂的对话需要进行共指解析。简单来说,就是某一个槽位的槽值与另一个槽位的槽值相同,所以使用一个 N 元(槽位的数量)分类器,用于计算当前槽位的槽值是否指向另外一个槽位。事实上,这与 System Inform Memory for Value Prediction 类似,都是解决共指解析。
Auxiliary Features
辅助特征。个人认为这种特征没什么特别大的意义。
Dialog State Update
使用与 Chao and Lane (2019) 同样的规则更新机制。每轮,如果槽值不为 none,则更新槽值;否则不更新。
总结
这模型与 TRADE 之类的 span-based 或者 open-vocabulary 模型有点不同。这个模型需要为每个域槽对都设计一个分类器,即有 \(N\) 个权重矩阵,然后将 \([CLS]\) 的特征输入每个分类器从而判断该域槽对是否被用户提取。而 TRADE 的做法是捕获域槽对的隐藏状态,然后将该隐藏状态 \(h^{dec}\) 输入一个分类器从而判断该域槽对是否被用户提取。粗体就是区别,一个输入的是 \([CLS]\) 特征,其是固定的,只能使用不同的权重矩阵来判断不同的域槽对,另一个输入的是域槽对的隐藏状态 \(h^{dec}\),由于域槽对是不同的,则 \(h^{dec}\) 也是不同的,所只需要一个分类器即可。
Multi-domain Dialogue State Tracking as Dynamic Knowledge Graph Enhanced Question Answering
本文将多领域 DST 视为问答问题,被称为 Dialogue State Tracking via Question Answering(DSTQA)。在 DSTQA 之中,每一轮生成一个问题,询问域槽对的槽值,因此可以很自然地将其扩展到未知领域,槽位和槽值。此外,我们使用一个动态变化的知识图谱,以清楚地学习槽值对之间的关系。
- 公式阐述:在多领域 DST 问题中,有 \(M\) 个领域 \(D=\{d_1, d_2, \cdots, d_M\}\)。每个领域 \(d \in D\) 有 \(N^d\) 个槽位 \(S^d=\{s^d_1, s^d_2, \cdots, s^d_{N^d}\}\)。每个槽位 \(s \in S^d\) 有 \(K^s\) 个可能的值 \(V^s=\{v^s_1, v^s_2, \cdots, v^s_{K^s}\}\)。对话 \(X\) 定义为 \(X = \{U^a_1, U^u_1, U^a_2, U^u_2, \cdots, U^a_T, U^u_T\}\)。
MA-Dst: Multi-Attention-Based Scalable Dialog State Tracking
研究目的 捕获对话历史与语义槽位之间的关联。
研究方法 1)对话历史和槽位编码器使用三阶段的 attention 机制捕获多粒度特征;2)然后利用 slot gate 和 decoder 解码槽值(与 TRADE 类似)。
Encoders
对话历史 \(C_t\) 和 槽位 \(s_i\) 编码器使用三阶段 attention,分别是 word-level cross-attention,higher level cross attention 和 self-attention。
Enriched Word Embedding Layer
对于 \(C_t\) 和 \(s_i\),首先将单词映射为低维表征,分别使用 300d GloVE,100d 字符嵌入。对于 \(C_t\),还添加了 5d POS tag 嵌入,5d NER tag 嵌入 和 5d turn_id 嵌入。
为了捕获单词的上下文嵌入,使用了 ELMo 嵌入。最后的词嵌入是以上所有嵌入的拼接。
Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking
作者:Zhang et al., 2019。
现存的 DST 方法分为两种类型:picklist-based 和 span-based。picklist-based 方法在预定义本体的条件下,为每个槽位上潜在的槽值执行分类任务。但是它在工业环境下,是不切实际的,因为很难获得对本体的完全访问。span-based 方法在对话上下文中,通过寻找一个文本跨度(text spans),为每个槽位跟踪槽值。然而,由于槽值的多样性,很难在对话上下文中找到一个合适的字符串。为了解决这一问题,通过借鉴前两者方法的优点,本文提出 Dual Strategy for DST (DS-DST)。
本文的做法:将域槽对视为 picklist-based 槽位或者 span-based 槽位,决定域槽对类别归属的方法是凭借人类启发(human heuristics)。
例如在订酒店的场景下,请求一个停车位通常只有“yes”或者“no”的回复,所以将此类槽位视为 picklist-based 槽位。鉴于用户停留的天数是无限的,并且可以在上下文中找到,所以将其视为 span-based 槽位。
DS-DST:令 \(X = \{(U^{sys}_1, U^{usr}_1), \cdots, (U^{sys}_T, U^{usr}_T)\}\) 代表系统语句 \(U^{sys}_t\) 和 用户语句 \(U^{usr}_t\) 的集合(\(1 \le t \le T\)),在给定 T 轮对话的情况下。令 N 个可能的域槽对表示为 \(S = \{S_1, \cdots, S_N\}\),其中,每个域槽对都有 n 个符号。
DST 是追踪整个对上的状态,因此每一轮,我们都需要在上下文 \(X_t = \{(U^{sys}_1, U^{usr}_1), \cdots, (U^{sys}_t, U^{usr}_t)\}\) 中预测每个域槽对 S 的槽值,其中 \(X_t\) 拥有 m 个符号。我们假定 span-based 槽位在 S 中有 M 个,picklist-based 槽位有 N-M 个。每个 picklist-based 槽位有 C 个可能的槽值,即 \(V_1, \cdots, V_C\),其中 C 是 picklist 的容量,每个槽值有 c 个符号。
我们首先使用 BERT 编码对话上下文 \(X_t\) 的信息,编码时还考虑了 S 中每个域槽对,以此获取基于域槽对信息的上下文表征。然后使用 slot gate 处理特殊类型的槽值。对于 span-based 槽位,使用 two-way 线性映射以找到文本跨度。对于 picklist-based 槽位,我们基于上下文表征从 picklist 中选择可信的槽值。
Slot-Context Encoder
请注意,DS-DST 的做法是将所有域槽对中的一个与上下文拼接起来,并使用 BERT 获取特征,然后将 \(r^{CLS}\) 输入进一个线性层,以此计算该域槽对的 slot gate 是什么。最后,对于每一个域槽对都需要进行以上的操作。博主注:但是这样好像并行起来比较困难?
而 TRADE 的做法是将域槽对单独拿出来,使用词向量表示,然后使用域槽对词向量与上下文执行 attention 机制,以此获得一个上下文向量。最后再使用该向量进行分类,从而得到 slot gate。
个人认为还是 TRADE 的方法更合理一点。
对于第 j 个域槽对以及 t 时的对话上下文,我们使用 BERT 进行编码,将二者拼接,然后获取表征: \[R_{tj} = BERT([CLS] \oplus S_j \oplus [SEP] \oplus X_t) \tag{1} \]
其中 [CLS] 是一个特殊符号,每个样本之前都应该有它,[SEP] 是一个特殊的分割符。公式 1 中的输出可拆解为 \(R_{tj} = [r^{CLS}_{tj}, r^1_{tj}, \cdots, r^k_{tj}]\),其中 \(r^{CLS}_{tj}\) 代表 K 个输入的聚合表征(博主注:这个只是一个定义而已),\(r^k_{tj}\) 就是普通的符号表征。
Slot-Gate Classification
多领域对话中有非常多的域槽对,很不容易判断一个域槽对是否出现在每一轮的对话中。总的来说,在 t 轮,我们让分类器在 {none, dontcare, prediction} 中做出决策。none 代表没有提及,dontcare 代表对于某槽位用户可以接受任何槽值,prediction 代表应该由模型处理。我们在 slot-gate classification 中利用 \(r^{CLS}_{tj}\),t 轮中第 j 个域槽对的概率由如下公式计算: \[P^{gate}_{tj} = softmax(W_{gate} \cdot (r^{CLS}_{tj})^T + b_{gate}) \tag{2}
\]
此分类器的 loss 函数为: \[\mathcal{L}_{gate} = \sum^T_{t=1} \sum^N_{j=1} -log(P^{gate}_{tj} \cdot (y^{gate}_{tj})^T) \tag{3} \]
其中 \(y^{gate}_{tj}\) 是第 t 轮第 j 个域槽对的 one-hot 标签。
Span-Based Slot-Value Prediction
计算 start 和 end 位置的向量: \[[\alpha^{start}_{tj}, \alpha^{end}_{tj}] = W_{span} \cdot ([r^1_{tj}, \cdots, r^k_{tj}])^T +b_{span} \tag{4} \]
那么,start 的概率可以使用公式:\(P^{start}_{tj} = \frac{e^{\alpha^{start}_{tj} \cdot r^i_{tj}}}{\sum_k \alpha^{start}_{tj} \cdot r^k_{tj}}\) 得到(博主注:这应该是 softmax,所以他可能漏了个 e,正确公式我认为是这样的:\(P^{start}_{tj} = \frac{e^{\alpha^{start}_{tj} \cdot r^i_{tj}}}{\sum_k e^{\alpha^{start}_{tj} \cdot r^k_{tj}}}\)),因此此模型的 loss 为(end 类似,不再赘述): \[\mathcal{L}_{start} = \sum^T_{t=1} \sum^M_{j=1} -log(P^{start}_{tj} \cdot (y^{start}_{tj})^T) \tag{5} \]
Picklist-Based Slot-Value Prediction
首先获得候选值的聚合表征 \[Y_j = BERT([CLS] \oplus V_j \oplus [SEP]) \tag{6} \]
(余下略,写起来太麻烦了)
Training Objective
\[\mathcal{L}_{total} = \mathcal{L}_{sg} + \mathcal{L}_{span} + \mathcal{L}_{picklist} \tag{9}\]
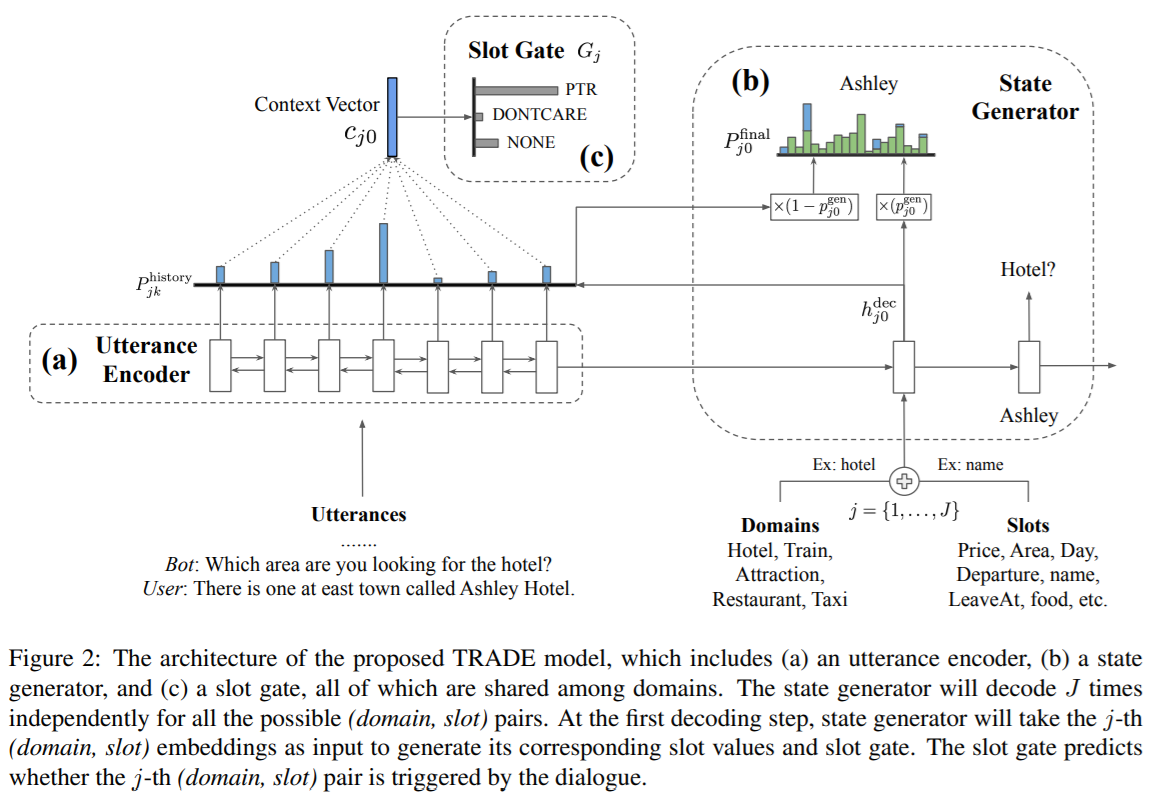
Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems
论文笔记。作者:Wu, Chien-Sheng et al., 2019。
Global-Locally Self-Attentive Dialogue State Tracker
作者:Zhong et al. 2018。
引言
- 在 DST 中,state 通常由一系列的 requests 和 joint goals 组成。
- DST 中的一个重要问题是,现存的方法没有解决对低频槽值的提取。这是因为任务导向的对话系统涵盖了巨大的状态空间,许多槽值对组成的状态在训练集中很少出现。尽管用户一轮对话指定一个低频槽值对的概率很小,但是他们在整个对话中指定一个的概率很大。
- 本文提出 Global-Locally Self-Attentive Dialogue State Tracker(GLAD) 。相比于先前的工作, GLAD 独立地估计每一个槽值,使用 global modules 在估计器之间为每一个槽位共享参数,使用 local modules 学习特定槽位的表征。
GLAD
GLAD 对每对槽值使用了一个估计器,将多元状态分类分解为一系列的二元分类问题,以此跟新状态。
- Global-Locally Self-Attentive Encoder:每个状态都由一系列的槽值对组成,它们中有许多都是低频的,这会造成误差在多轮对话中累积。为了解决这一问题,使用 global module 对每个槽位进行参数共享,使用 local module 学习特定槽位的特征。使 n 代表序列长度, \(d_{emb}\) 为词向量维度,\(X \in \mathbb{R}^{n \times d_{emb}}\) 为序列中所有单词的词向量矩阵。我们使用 Bi-LSTM 产生 X 全局编码 \(H^g\),其中 \(d_{rnn}\) 代表 LSTM 隐藏状态的维度。以同样的方法产生 X 的局部编码 \(H^s\),这考虑的是槽位 s。然后二者通过一个混合函数产生一个 X 的 global-local 编码 H,其中 \(\beta^s\) 是一个特定于槽位 s 的 01 之间的可学习参数。公式如下所示: \[
\begin{align}
H^g & = biLSTM^g(X) \in \mathbb{R}^{n \times d_{rnn}} \tag{1} \\
H^s & = biLSTM^s(X) \in \mathbb{R}^{n \times d_{rnn}} \tag{2} \\
H & = \beta^s H^s + (1 - \beta^s)H^g \in \mathbb{R}^{n \times d_{rnn}} \tag{3} \\
\end{align}
\] 接下来计算 H 的 global-local self-attention context \(c\)。self-attention(或称 intra-attention) 是一种计算变长序列长下文摘要的好方法。对于第 i 个元素 \(H_i\),我们计算全局自注意力分数标量 \(a^g_i\),之后通过 softmax 将所有元素归一化,global self-attention context(下称全局自注意力上下文)\(c^g\) 就通过加权和计算出来了。 local self-attention context(下称局部自注意力上下文)\(c^s\) 同理。而 global-local self-attention context \(c\) 是它们的混合。计算公式如下所示: \[
\begin{align}
a^g_i & = W^g H_i + b^g \in \mathbb{R} \tag{4} \\
p^g & = softmax(a^g) \in \mathbb{R}^n \tag{5} \\
c^g & = \sum_i p^g_i H_i \in \mathbb{R}^{d_{rnn}} \tag{6} \\
a^s_i & = W^s H_i + b^s \in \mathbb{R} \tag{7} \\
p^s & = softmax(a^s) \in \mathbb{R}^n \tag{8} \\
c^s & = \sum_i p^s_i H_i \in \mathbb{R}^{d_{rnn}} \tag{9} \\
c & = \beta^s c^s + (1 - \beta^s) c^g \in \mathbb{R}^{d_{rnn}} \tag{10}
\end{align}
\] 为了便于说明,我们定义了函数
encode(X),它将序列 X 映射为编码 H 和自注意力上下文 c: \[encode: X \to H, c \tag{11} \] - Encoding module:定义好 global-locally self-attentive encoder 之后,我们可以构建用户语句、上一轮系统动作和槽值对的表征了。使 \(U\) 代表用户语句的嵌入,\(A_j\) 代表上一轮系统的第 j 个动作(例:request(price range)),\(V\) 代表槽值对(例:food=french)。所以我们有公式: \[ \begin{align} H^{utt}, c^{utt} & = encode(U) \tag{12} \\ H^{act}_j, C^{act}_j & = encode(A_j) \tag{13} \\ H^{val}, c^{val} & = encode(V) \tag{14} \\ \end{align} \]
- Scoring module:该组件,直观来说,我们可以通过检查两个输入,判断用户是否表达出了槽值对。第一个输入是用户语句,用户直接陈述目标与请求。做法是判断用户是否指定了某个槽值对。考虑用户语句 \(H^{utt}\),槽值对 \(c^{val}\),最后使用 resulting attention context \(q^{utt}\) 计算槽值对的分数,其中 m 代表用户语句中单词数量,分数 \(y^{utt}\) 代表用户表达槽值对的程度。公式如下所示: \[ \begin{align} a^{utt}_i & = (H^{utt}_i)^T c^{val} \in \mathbb{R} \tag{15} \\ p^{utt} & = softmax(a^{utt}) \in \mathbb{R}^m \tag{16} \\ q^{utt} & = \sum_i p^{utt}_i H^{utt}_i \in \mathbb{R}^{d_{rnn}} \tag{17} \\ y^{utt} & = W q^{utt} + b \in \mathbb{R} \tag{18} \\ \end{align} \] 第二个输入是前一轮系统动作。这在用户没有提供信息,但是提到先前系统动作时很有效。如:在系统询问“你喜欢在市中心的酒店吗”,用户回答“喜欢”。为了处理这种情况,考虑动作表征 \(C^{act} = [C^{act}_1, \cdots, C^{act}_l]\) 以及用户语句上下文 \(c^{utt}\),\(l\) 是动作数量,然后使用 \(q^{act}\) 和 \(c^{val}\) 之间的相似度来衡量槽值对: \[ \begin{align} a^{act}_j & = (C^{act}_j)^T c^{utt} \in \mathbb{R} \tag{19} \\ p^{act} & = softmax(a^{act}) \in \mathbb{R}^{l+1} \tag{20} \\ q^{act} & = \sum_i p^{act}_j C^{act}_j \in \mathbb{R}^{d_{rnn}} \tag{21} \\ y^{act} & = (q^{act})^T c^{val} \in \mathbb{R} \tag{22} \\ \end{align} \] 除了真实的动作,我们还引入了哨兵动作以忽略上一轮的系统动作。\(y^{act}\) 代表上一轮动作表达了某个槽值的程度。最后的 y 使用二者的加权和,使用 sigmoid 函数归一化,w 是可学习参数。 \[y = \sigma(y^{utt} + w y^{act}) \in \mathbb{R} \tag{23} \]
总结
虽然文中没有明确指出,但是 global Bi-LSTM 应该是所有的槽位共享一个模型,而 local Bi-LSTM 应该指的是对于每一个槽位都训练一个模型。最后从文中的实验结果发现,似乎 global 组件对于 request 的实验结果毫无影响???
Scalable multi-domain dialogue state tracking
已删除
Neural Belief Tracker: Data-Driven Dialogue State Tracking
论文笔记。作者:Mrkšić N et al., 2016。
Incremental LSTM-based dialog state tracker
作者:Zilka and Jurcicek, 2015。
此论文是作者同年发表的论文的扩展,他们将论文中的状态跟踪器称为 LecTrack。它能一个接一个地处理单词,这其实是 RNN 的特性,也是论文名中“Incremental”的起因。 本文定义:在第 t 轮,对话状态 \(s_t \in C_1 \times \cdots \times C_k\) 为一个向量,包含 k 个元素,有时候在文献中它们被称为槽位(slot)。每个 \(c_i \in C_i = \{v_1, \cdots, v_{n_i}\}\) 包含 \(n_i\) 个槽值,并且我们假设各成分(slot)之间是独立的,则: \[P(s_t | w_1, \cdots, w_t) = \prod_i p(c_i | w_1, \cdots, w_t; \theta) \]
LSTM dialogue state tracker:
- model:使用 LSTM 提取语句信息,但是做了小小的改动,将输入门的 sigmoid 函数换做了 tanh。公式如下所示: \[
\begin{align}
u & = NN(a, r) \\
q_t & = Enc(u, q_{t-1}) \\
p_t & = C(h_t) \\
\end{align}
\] 其中单词 a 与其 ASR 置信度分数 r 的联合表征为 u,LSTM decoder 使用 u 以及前一时间步的隐藏状态 \(q_{t-1} = (c_{t-1}, h_{t-1})\) 计算出当前隐藏状态 \(q_t\),C 代表 softmax 层,将隐藏状态映射为各个可能值的分布。
注意,虽然论文中没有明确写出,但是对于最后一个公式 \(p_t = C(h_t)\),它可能需要为每一个槽位都设计一个函数。这个公式应该是这样的:\(p^j_t = C(h_t), \forall j \in 1, \cdots, k\),j 代表槽位索引,t 代表单词在句子中的索引。
- Improvements:1)包括了 ASR 置信度分数;2)将训练集中的 Transcriptions 加入训练;3)多个模型取均值;4)低频词抽象化
模型流程(个人向):输入每个单词,输出对应的隐藏状态。隐藏状态经过一个函数输出槽值的分布,这个函数是特定于槽位的。也就是说每个槽位都有一个独一无二的函数,在生成槽值时,只需要遍历所有槽位的函数,然后将隐藏状态传入每一个函数,就可以得到每个槽位对应的槽值分布。
Word-Based Dialog State Tracking with Recurrent Neural Networks
之前的论文大都是使用 SLU 的结果作为输入,这篇论文则直接使用 ASR 的结果作为输入。据我所知这篇论文应该是首创。这种做法的好处是,消除了 ASR 到 SLU 的误差 [4]。
近来 DST 领域的辨别式方法已经展示出了超于传统的生成式方法的性能。本文提出 word-based DST,直接从 ASR 结果映射到对话状态。使用 RNN 结构,有能力泛化到未见的对话状态假设,只需要一点特征工程。
通常,DST 假定 SLU 将 ASR 的假设映射为一系列的语义假设,本论文直接将 ASR 的假设映射为对话中某轮的对话状态,省略了中间 SLU 的处理步骤。这避免了显式语义表征的需要以及在 SLU 阶段可能的信息误差。
与用户交流时,统计对话系统必须维护一个潜在的对话状态的分布,这个步骤被称为 DST。这个分布有时候也被称作 belief state (划重点要考),直接决定了系统的决策。
介绍了一堆 14 年前的做法以及区别。
Feature Representation(1-2)/Generalisation to Unseen States(3):
- 如图 1 所示,从 ASR 的 N-best 列表中提取出 n-gram 特征,即为每个假设计算 uni-/bi-/tri-gram。然后用 N-best 列表的概率计算加权和求得到单个向量。如果出现了相同的项,把对应的概率相加即可。
- 此领域的 dialogue acts 由形如 acttype(slot=value) 的一系列 act 成分组成,其中 slot=value 是可选的。n-gram 正是提取自这些成分,如:
'acttype', 'slot', 'value', 'acttype slot', 'slot value'和'acttype slot value'或者对于acttype()只有'acttype'。处理方法与 1 类似,只是它们的权重都置为 1 - 处理未在训练集出现的状态(如一种食物类型)的方法是:使用 'tagged' 方法,即忽略特定的槽值,将其替换为类似
<value>的标签。如图 1 所示,\(f_s, f_v\) 来自未标过的 \(f\)。
Model Definition:
- RNN 拥有一个内部的记忆 \(m \in \mathbb{R}^{N_{mem}}\)。如果对于槽位 s 有 N 个槽值,那么概率分布输出 \(p \in \mathbb{R}^{N+1}\),其中最后一个成分 \(P|_N\) 代表 None。图 2 解释了 p 和 m 在某一轮中是如何被更新为 p' 和 m' 的。
- 神经网络的一部分结构用于学习将 untagged input, memory, previous state 映射为向量 \(h \in \mathbb{R}^N\),它将直接参与 \(p'\) 的计算。公式为:\(h=NNet(f \oplus p \oplus m) \in \mathbb{R}^N\)。(博主注:h 学习将 lexical n-grams 映射为特定的槽值对,此步可能对 domain-independent 具有一定的影响,故这篇论文移除了这部分的网络)
- 本文 \(NNet(\cdot)\) 均代表激活函数为 sigmoid 的隐藏层
- 其次,由于 h 的计算需要使用训练集中每一个槽值的样本,所以泛化性并不好。通过 g,采用 tagged feature 作为输入,可能可以提高泛化性。对于一个槽位的槽值 v,计算公式为:\(g|_v = NNet(f \oplus f_s \oplus f_v \oplus \{p|_v, P|_N\} \oplus m) \in \mathbb{R}\)。此结构的网络能够处理未见或者不频繁的 dailogue state
- 博主注:不同的槽位拥有不同模型,即其中的每个 p 都不同
- new belief \(p'\) 的更新公式为:\(p' = softmax([h+g] \oplus \{B\}) \in \mathbb{R}^{N+1}\),其中 B 是 RNN 的一个参数,有助于 None 的假设的估计
- 最后 memory 的更新公式为:\(m' = \sigma(W_{m0}f + W_{m1}m) \in \mathbb{R}^{N_{mem}}\),其中 \(W_{mi}\) 是 RNN 的参数
