什么是迁移学习
现在手上有一些与本实验没有直接关系的数据集,那么能不能使用该数据集来帮助我们做一些事情。
比如说要开发一个图像识别的模型,去识别医学上的图像。这方面的数据集可能很少,但是作为图片本身来说是有很多的。比如猫狗图片也是图片。
概要
与任务有关的数据被称为 target data,与任务没有直接关系的数据被称为 source data。每种数据都有可能有标签和无标签,所以一共分四种情况。 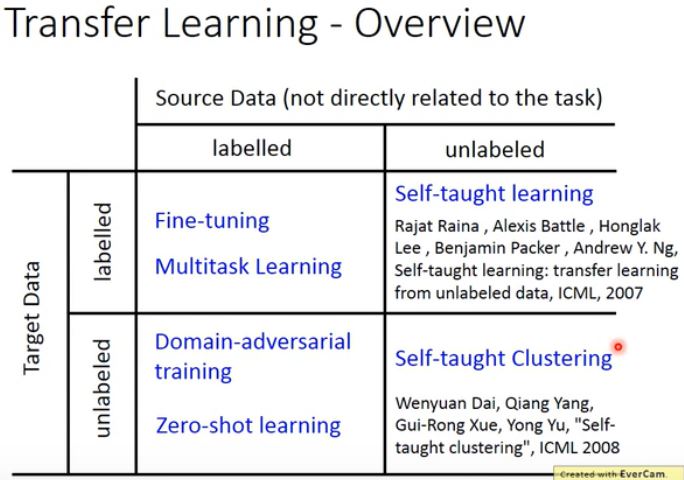
都有标签
Target data 和 Source data 都具有标签。 任务定义为:Target data:\((x^t, y^t)\) 和 Source data:\((x^s, y^s)\)。
Fine-tuning
最常见以及最简单的做法是微调。Fine-tuning 在乎的是在 Target data 上的性能好不好,如果在 Source data 上的性能坏掉就算了。(25:00) 但是通常 Tartget data 的量是很少的,因为如果量多的话,直接当一般的机器学习方法来做就行了。总而言之,一般 Source data 的量会有很多。此外 Target data 很少,大概只有几个样本一般叫做 One-shot learning。 例如,Target data 是音频数据,并且是特定用户的声音,而 Source data 是许多人的声音。这里的处理方式是使用 Source data 来训练一个模型,然后使用 Target data 来微调。但是这可能会有个问题,当你使用 Target data 继续训练时,整个模型可能会坏掉。 接下里介绍一些可能能够解决的技巧: - Conservative Training:比如在语音辨识的任务中,使用 Source data 训练一个神经网络,这些数据都随处可见。但是你的 Target data 可能是用户特定的声音,可能只有 5 句、10 句。当然如果直接使用 Target data 训练模型肯定也是不行的,注意这个模型已经是之前使用 Source data 预训练的模型。(李宏毅老师没说为什么。)所以我们在微调的时候,需要加入一些正则化约束。通常我们会加 L1 和 L2,但是在 Consertive Training 中我们会加不同的正则化。总而言之,我们需要使得两个模型之间的输出时接近的,或者模型参数是接近的。(具体怎么做,他也没说。) 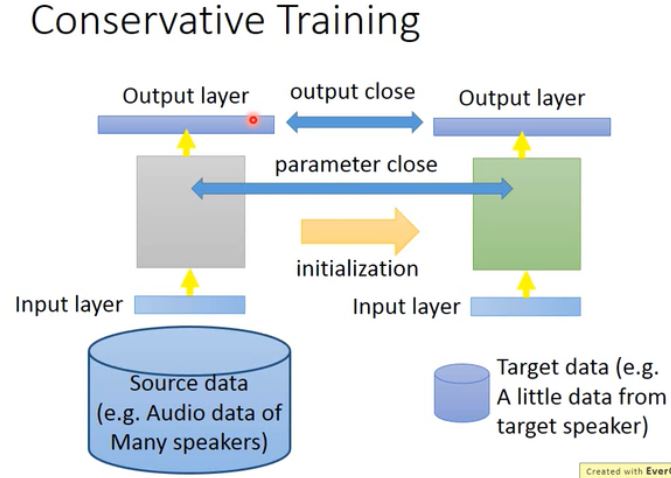 - Layer Transfer: 把模型中某几个 layer 拿出来,直接复制到新的模型中。1)然后使用 Target data 只训练自己定义的那几层 layer(防止过拟合);2)当然如果你有足够多的 Target data,你也可以微调整个模型。
- Layer Transfer: 把模型中某几个 layer 拿出来,直接复制到新的模型中。1)然后使用 Target data 只训练自己定义的那几层 layer(防止过拟合);2)当然如果你有足够多的 Target data,你也可以微调整个模型。 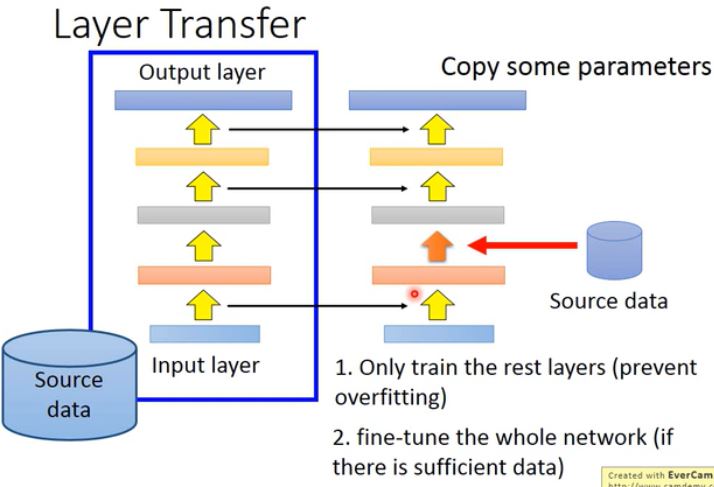 + 那么哪些 layer 应该被 transfer 呢? * Speech:通常拷贝最后几层,然后重新训练 input 的那层。因为在语音识别中,人的发音均有不同,而模型的前几层可能与人的发音(浅层信息)有关。后几层可能与特定的人无关(深层信息)。 * Image:通常拷贝前几层,然后重新训练后几层。因为在机器视觉里,前几层可能捕获的是图片的浅层信息,而这些信息每个人看到的几乎都是一样。后面几层可能是深度的信息,每个任务需要的信息可能都是不同的。
+ 那么哪些 layer 应该被 transfer 呢? * Speech:通常拷贝最后几层,然后重新训练 input 的那层。因为在语音识别中,人的发音均有不同,而模型的前几层可能与人的发音(浅层信息)有关。后几层可能与特定的人无关(深层信息)。 * Image:通常拷贝前几层,然后重新训练后几层。因为在机器视觉里,前几层可能捕获的是图片的浅层信息,而这些信息每个人看到的几乎都是一样。后面几层可能是深度的信息,每个任务需要的信息可能都是不同的。
Multitask Learning
Multitask Learning 在乎的是在两个数据集上是否做得都好。 假设现在两个不同任务使用的是同样的 feature 的话(图左)。在叠几层神经网络后,在某一层分成两个任务做。那么这两个任务在前几层是共用特征的。所以在做 Multitask Learning 时,需要确定两个任务是否具有共通性,是否可以共用前几个 layer。 甚至现在有一些更疯狂的做法(图右)。模型的输入都可能没有办法共同学习,但是可以把两个特征输入进同一个模型,然后仅在某几层共享它们的特征。就算 task A 和 B 的输入特征完全不一样,但是只要你觉得在中间某几层有几个共同的地方,你还是可以用 Multitask Learning。 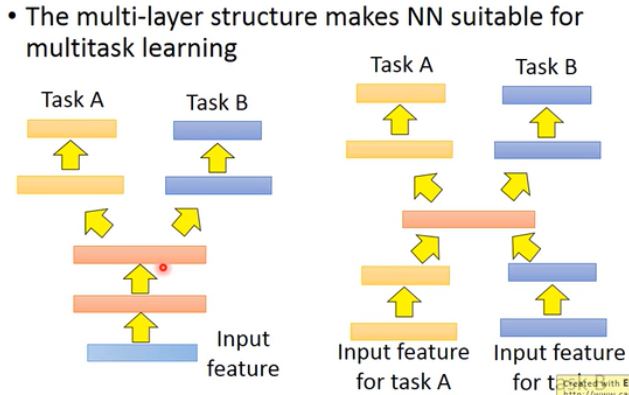
Multitask Learning 比较成功的案例是多语言语音识别。
Progressive Neural Network
Source data有标签
任务定义为:Source data:\((x^s, y^s)\),Target data:\((x^t)\)。 
