目前所记录的论文只截止到 2020 年。此外,还有情感计算论文调研的文章。
2021.04.08 更新:此篇文章大概不会再更新,因为博主转做任务型对话了。(;д;)
Towards Persona-Based Empathetic Conversational Models
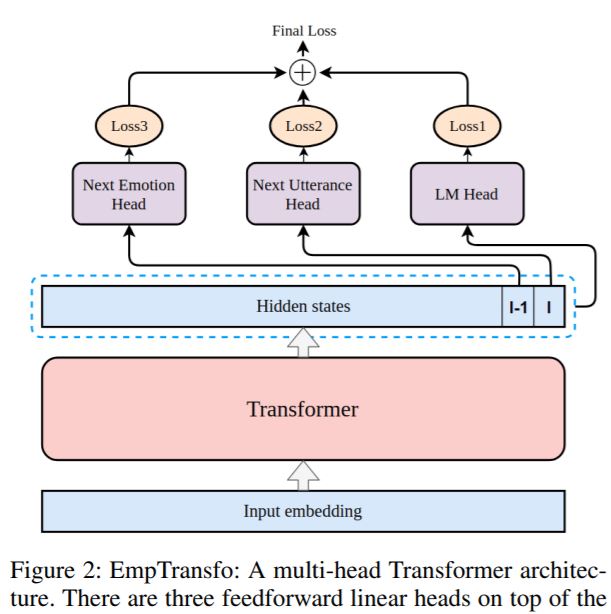
EmpTransfo: A Multi-head Transformer Architecture for Creating Empathetic Dialog Systems
CAiRE: An Empathetic Neural Chatbot

- Language Model Pre-training:使用 GPT,在大型文本语料库 BooksCorpus 上进行预训练,可以使得模型能够捕获对话跨度足够大的上下文信息。
- Persona Dialogue Pre-training:现存的移情对话数据集相对较小,仅在这数据集上进行微调可能会限制模型在闲聊时的所拥有的话题。为了增强 CAiRE 在闲聊时的能力,参照 Wolf et al., 2019 的迁移学习策略,我们先在 PersonaChat 上对模型进行预训练。该预训练步骤给予 CAiRE 一个 persona,因此提高了模型的参与度和一致性。
- Empathetic Dialogue Fine-tuning:使用 EmpatheticDialogues。在训练的时候给出 speaker 的情绪标签,但是在评估时,不给出。
- Fine-tuning Detail
- 为了完全利用在 PersonaChat 上预训练的效果,我们自定义了 CAiRE 的 persona 语句:"my name is caire", "i want to help humans to make a better world", "i am a good friend of humans"(博主注:这些语句代表着 CAiRE 的人物定位)。照着 Wolf et al., 2019 的微调协议,我们首先拼接了自定义 persona,对话历史以及回复(distractor)。使用了特殊符号,并且所有的嵌入都是由位置嵌入,词嵌入和对话状态嵌入相加而成。前两个是 Transformer 所需,对话状态嵌入帮助 CAiRE 对对话的体系结构建模,同时用于区分 persona 语句,对话上下文语句和回复。表征输入进 Transformer 后生成上下文表征,我们将最后一个符号定义为 \(SEN\),回复(distractor)之前的符号定义为 \(EMO\)。
- 为了优化回复预测的目标对象,在每一个训练步,我们从其他对话中采样出一个 distractor 来对抗真实的回复。然后将 SEN 表征输入一个线性层,区分是否为真实的回复,然后得到 cross-entropy \(\mathcal{L}_S\)。
- 为了优化回复的语言模型的目标对象,我们用真实回复的上下文表征去预测下一个回复的符号,然后使用 cross-entropy 计算语言模型的 loss \(\mathcal{L}_L\)。
- 为了使 CAiRE 探测到对话伙伴的情绪,我们在训练阶段新增了一个对话情绪探测优化目标。我们将 EMO 作为当前对话状态的摘要,然后将其输入进线性映射层,去预测 32 个情绪的分数。cross-entropy 被用于计算情绪类别的 loss \(\mathcal{L}_E\)
- 最终,我们在最后的 loss 函数上进行微调:\(\mathcal{L} = \alpha \mathcal{L}_L + \mathcal{L}_S + \mathcal{L}_E\)
- Fine-tuning Detail
MoEL: Mixture of Empathetic Listeners

- 以前的移情对话系统研究大多数关注的是给定某个情绪,生成一个回复。然而要使得系统具有移情能力,更重要的是需要理解用户的情绪以及合适的回复。本文提出一个 end-to-end 方法,用于对移情对话系统建模,即 Mixture of Empathetic Listeners(MoEL)。我们的模型首次捕获了用户的情绪并且输出一个情绪分布。
- 目前移情对话回复生成主要有两条线:1)多任务方法,联合训练一个模型,预测用户当前的情绪状态以及基于此状态合适的回复;2)调节对某一固定情绪的回复生成。
- Mixture of Empathetic Listeners:对话上下文是一组来自 Speaker 和 listener 的交替语句,表示为 \(\mathcal{C} = \{U_1, S_1, U_2, S_2, \cdots, U_t\}\),speaker 每句话的情绪状态表示为 \(Emo = \{e_1, e_2, \cdots, e_t\}, \, \forall e_i \in \{1, \cdots, n\}\)。我们的模型旨在追踪上下文中 speaker 的情绪状态 \(e_t\),并且生成一个移情回复 \(S_t\)。总的来说,如图 1 所示,MoEL 由三个组件组成:emtion tracker, emotion-aware listeners and meta listener。1)emtion tracker 编码 \(\mathcal{C}\) 以及计算用户情绪的分布。2)emotion-aware listeners 独立地关注上述分布并计算它们自己的分布。3)最后,meta listener 采用来自 emotion-aware listeners 的加权表征,然后生成最终的语句。模型架构 任务定义和介绍模型计算流程
- Embedding:定义上下文嵌入为 \(E^C \in \mathbb{R}^{|V| \times d_{emb}}\),回复的嵌入为 \(E^R \in \mathbb{R}^{|V| \times d_{emb}}\)。在多轮对话中,模型能够区分不同的轮数是至关重要的。因此我们在输入中加入了对话状态的嵌入,这被用于使 encoder 能够区分 speaker 或者 listener 的语句(Wolf et al., 2019)。此外还加入了位置编码,所以上下文嵌入表示为 \(E^C(C) = E^W(C) + E^P(C) + E^D(C)\)。\(E^W\) 代表词向量,\(E^P\) 代表位置编码,\(W^D\) 代表对话状态(对话状态指的是什么,请参考 Wolf et al., 2019)。
- Emotion Tracker:此模块使用标准的 Transformer。首先拼接所有对话轮数,使用 \(E^C\) 将所有符号映射为向量表征。然后开始编码。类似 BERT,为了计算输出张量的加权和,我们在每一个输入序列的开头增加了一个 query 符号 \(QRY\)。将 Transformer 的编码器表示为 \(TRS_{Enc}\),那么对应上下文表征如下所示,\(H \in \mathbb{R}^{L \times d_{model}}\),其中 L 是序列长度。 \[H = TRS_{Enc}(E^C([QRY; C])) \] 那么我们可以定义符号 \(QRY\) 最后的表征为:\(q = H_0, q \in \mathbb{R}^{d_{model}}\),然后它被用于生成情绪的分布。
- Emotion Aware Listeners:这主要由 1)shared listener(学习每个情绪的共享信息);2)n 个独立的 Transformer decoder(学习在给定一个特定的情绪状态下,做出合适的反应)组成。我们定义 listeners 的集合为:\(L = [TRS^0_{Dec}, \cdots, TRS^n_{Dec}]\)。每个情绪回复表征为: \[V_i = TRS^i_{Dec}(H, E^R(r_{0:t-1}))
\] \(TRS^i_{Dec}\) 指的是第 i 个 listener,包括 shared listener。在概念上,我们希望 shared listener 的输出是一个通用表征,可以帮助模型捕获对话上下文。而每个 empathetic listener 的职责是学习怎样用某种情绪进行回复。为了使模型拥有这些行为,我们根据用户的情绪分布给不同的 empathetic listener 分配了不同的权重,但是给 shared listener 分配固定的权重 1。(这个权重在最后加权和的时候用)
- 构建了一个 Key-Value Memory Network(Miller et al., 2016),用于为 listener 分配不同的权重。
- Meta Listener:最后,该组件使用的是另一个 Transformer decoder,它进一步地转换了 listeners 的表征并且生成了最后的回复语句。直觉是每个 listener 专门针对某种情绪,meta listener 收集多个 listener 的意见,并产生最终的回复。此模块的公式定义类似。
~I kown the feeling: Learning to converse with empathy

~Towards Empathetic Open-domain Conversation Models: a New Benchmark and Dataset
同上一篇论文,它们是一样的。
Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory
- 论文笔记
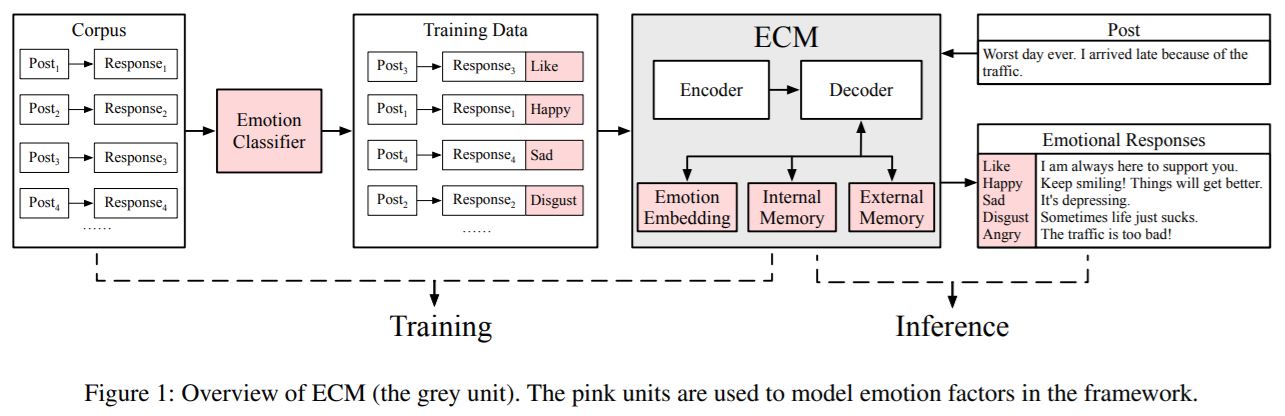
- 他们的模型定义为 \(P(Y|X, e) = \prod^m_{t=1} P(y_t | y_{<t}, X, e)\),Y 是回复,X 是用户输入,e 是情绪类别的嵌入(该论文假定 e 已经预先给定)。直观来说就是在给定用户输入语句和待生成回复的情绪类别(emotion categories)的条件下,生成回复(当然这几乎是不切实际的,因为你无法预先知道机器的回复需要附带什么样的情绪,所以这个类别 \(e\) 我该分配什么情绪?《Affective Neural Response Generation》也这么认为)。
- ECM 的工作流程是:1)在训练步骤,将语料输入情绪分类器,得到情绪,于是原语料变为 (post, response, emtion) 形式的三元组;2)在推理过程中,post 被输入进 ECM 以生成给予不同情绪类别的回复(博主注:此文章不可控制生成回复的情绪类别,只能为每一种情绪类别都生成一句合适的回复。比如说现在系统中定义了 5 种情绪类别,现在用户很悲伤,需要机器生成“安慰”的语句。但是 ECM 做不到,它只能遍历所有的情绪类别,然后为每一种类别生成一句回复)。
- Emotion Category Embedding 提取情绪类别的嵌入。
- Internal Memory 使用词向量,GRU 隐藏状态和上下文向量的拼接版进行计算。先使用 sigmoid 函数分别计算 read gate 和 write gate 的状态 \(g^r_t \, g^w_t\),然后 \(g^r_t\) 使用对应元素相乘的乘法(element-wise multiplication)从 Internal Memory \(M^I_{e,t}\) 中提取一定量的记忆 \(M^I_{r,t}\)(都是玄学,意会就行,不用试图理解),\(M^I_{r,t}\) 将与拼接版向量同时被喂入 GRU。最后 GRU 生成的隐藏状态 \(s_t\) 通过 \(g^w_t\) 提取出一定的记忆 \(M^I_{e,t+1}\) 写入 Internal Memory。受到心理学上的启发,情绪化回应是相对短暂的,所以凭借此 Internal Memory 记录用户交谈过程中的短暂情绪变化。之前说到该记忆状态 \(M^I\) 会与拼接后的向量同时输入进 GRU,这就意味着该情绪记忆会影响解码过程。特别地,该记忆模块不同于其他的记忆模块,如 LSTM,当解码过程结束后,记忆模块中的状态应该衰减至 0,这代表着情绪被机器完全地表达出来。

- External Memory 通过 GRU 的隐藏状态 \(s_t\) 计算下一个单词概率。单词的概率分布由两部分组成,一是情绪词表的概率分布,二是通用词表的概率分布,二者拼接后通过此拼接的概率分布计算下一个单词的概率。

TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents
此论文不算是情感计算的论文,由于上述有几篇论文用到了这论文的一些方法,所以这里也加进去了。
