本文来自前几篇博文的总结:
任务型对话系统简述
本节简要地概括任务型对话系统,梳理一遍其应用的各项技术。本文的重点是对话状态追踪算法。
信息技术发展的不断进步使人们能够在任何时间、地点以无线连接的方式几乎瞬时地访问信息、应用程序和服务。如今,诸如智能手机和平板电脑已经被广泛地用于访问网络。然而,内容的获取通常仅限于通过浏览器,其依靠传统的图形化界面(graphical user interfaces,GUIs)(López-Cózar et al. 2014)。更先进的人机交互方式亟需被提出,比如拥有更智能、直观和轻便的界面,能够以人类语言交流,提供透明且类人的环境。在影视作品中,通常呈现为智能机器人的形式。然而,目前的技术难以实现这种真正意义上的人类智能。因此,退而求其次,能够以自然语言与人类交流的对话系统受到青睐。
根据其所使用的技术,大致可以被分为基于规则的对话系统(第一代)、基于部分可见马尔可夫决策过程的统计对话系统(第二代)以及基于深度学习的对话系统(第三代)(Dai et al. 2020)。基于深度学习的对话系统与统计对话系统大致相同,只不过其中的各个模块被替换成神经网络模型。本文主要关注基于深度学习的对话系统。此外,由于系统涉及语音交互,在以前也被称为口语对话系统(spoken dialogue system,SDS)。
对话系统大致分为问答、闲聊和任务型三类,本文主要关注任务型对话系统(Task-oriented Dialogue System,TODS)。TODS 旨在为用户完成特定领域中的任务,例如酒店预订、天气查询、景点推荐等。TODS 一般有管道式(pipeline)和端到端(end-to-end)两种实现方式,由于端到端方式的不可控性,目前管道式 TODS 是主流的做法。管道式 TODS 分为六大模块:ASR、SLU、DST、DPL、NLG 和 TTS,每个模块前后相连。下图展示了系统的信息流动。通常,DST 和 DPL 也被并称为对话管理(Dialogue Management,DM)模块。
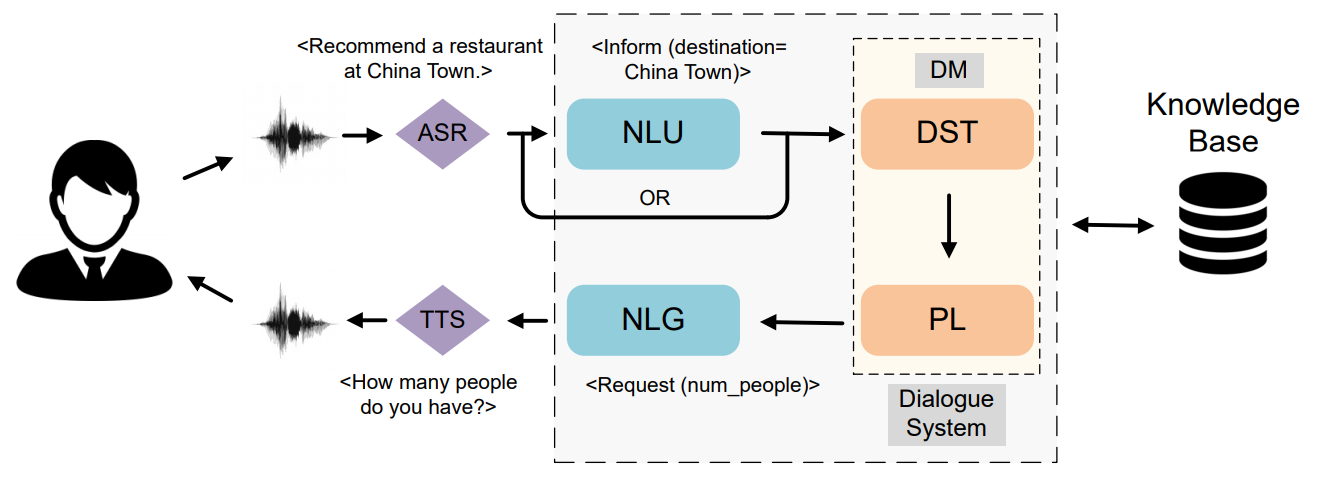
推荐看一些综述了解 TODS 的脉络。
- Review of spoken dialogue systems (López-Cózar et al. 2014):推荐看一下,是 2014 年的论文。它从生活应用角度讲述了 SDS 的必要性,介绍了大量深度学习时代以前的技术。内容包括:
- 各组件的实现技术
- 这些技术的发展并讨论一些现存的应用
- 讨论开发范式,包括脚本语言以及移动应用交互界面的开发
- 描述情感、人格和上下文模型
- 提出一些研究趋势
- A Survey on Dialogue Systems: Recent Advances and New Frontiers:暂时还没细看。
- A Survey on Dialog Management: Recent Advances and Challenges (Dai et al. 2020):主要介绍对话管理,总结了目前所面临的几项痛点。友情提示:知乎上有官方的中文版。
- Recent advances and challenges in task-oriented dialog systems (Z. Zhang et al. 2020)
- Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey (Ni et al. 2021)
引言
对话状态追踪(Dialogue State Tracking,DST)是 TODS 中一个至关重要的模块。它的目标是监控隐藏在对话历史中的用户目标,并将它们表示为由一系列 (domain, slot, value) 三元组组成的对话状态,读作(领域,槽位,槽值)。DST 与语音语言识别(Speech Language Understanding,SLU)紧密相关 (Ni et al. 2021 ch. 3.2) 并且十分相似,个人认为在预测用户目标任务上它们几乎等价。近年,为了避免 SLU 阶段的的误差传播到 DST,通常使用联合模型,即直接将文本或语音输入 DST 并省略 SLU。为此,DST 需要额外承担领域识别和意图识别两项任务。然而,据我所知,为了简便起见,近几年大部分 DST 论文并没有实现这两项任务。
DST 作为任务型对话系统中承上启下的组件,在科研领域中一直都是研究热点。在深度学习时代之前,DST 通常将 SLU 的输出作为输入,即一系列槽值对及其对应的置信度分数,然后使用基于规则或者基于统计的方式更新对话状态 (López-Cózar et al. 2014)。DST 只扮演了更新对话状态的角色。在进入深度学习时代之后,基于数据驱动的神经对话状态追踪开始成为主流,下如无特殊说明,将其简称为 DST。Henderson, Thomson, and Young (2013) 首次在 DST 中探索了深度学习方法 (Ni et al. 2021 ch. 3.2),使模型不再需要复杂的规则。Mrkšić et al. (2017) 借助词向量解决一义多词的现象,摆脱了人工构建语义词典的束缚。虽然以上工作减少了大量的人力成本并且取得了不错的表现,但仍旧:1)泛化能力不强;2)可扩展性不高;3)多领域 DST 是项挑战;4)数据集稀缺。
构建多领域 DST 的主要难点是数据稀缺。Rastogi, Hakkani-Tür, and Heck (2017) 使用三个不同的数据集(DSTC2、Sim-R,Sim-M)首次提出了一个多领域 DST 模型。Ramadan, Budzianowski, and Gašić (2018) 发布了当时最大的多领域数据集 MultiWOZ 1.0 并提出了一个多领域 DST 模型。之后在此基础上又更新了 MultiWOZ 2.0 (Budzianowski et al. 2018)、2.1 (Eric et al. 2019)、2.2 (Zang et al. 2020)、2.3 (Han et al. 2020) 以及 2.4 (Ye, Manotumruksa, and Yilmaz 2021)。基于 MultiWOZ 数据集,涌现了大量的多领域 DST 模型。此外,近年还有研究人员发布了中文任务型对话数据集,比如 CrossWOZ,RiSAWOZ (Quan et al. 2020)。
上文概述了传统 DST 模型以及基于深度学习的基本模型,然后提出了几项缺点并引出了多领域 DST,最后介绍了几种大规模任务型数据集。下文首先对近年(2017—)提出的各种 DST 模型进行归类总结,然后介绍一些 DST 增强技术,最后讨论一下近期的挑战,包括可扩展性、数据稀缺、计算复杂度等。模型的详细对比见下图,“-”代表没有数据,空白代表还没有看过对应内容,其它名词解释为:
- Method: cls=分类模型,gen=生成式模型,span=基于跨度的模型(PtrNet),disc=判别式模型。判别式模型的工作流程是计算槽位表征和槽值表征之间的距离。
- Aux Input: schema (ISV) 代表由 Rastogi et al. (2020) 提出的 schema,其中包含 intent,domain-slot,value。schema graph 仅代表领域和槽位。ds 和 dsg 分别指的是对话状态(dialog state)和对话状态图(dialog state graph)。
- Level: 在《DST分类·根据状态级别分类》中提到了。
- SG 代表 slot gate,或者是 slot gate 的替代。√ 代表使用了最常见的 slot gate,× 代表没有使用任何 slot gate 机制。N/A 代表模型不必使用 slot gate。
- 模型排序:以 MultiWOZ 2.2 为准,如果没有结果,则按其他结果排序。
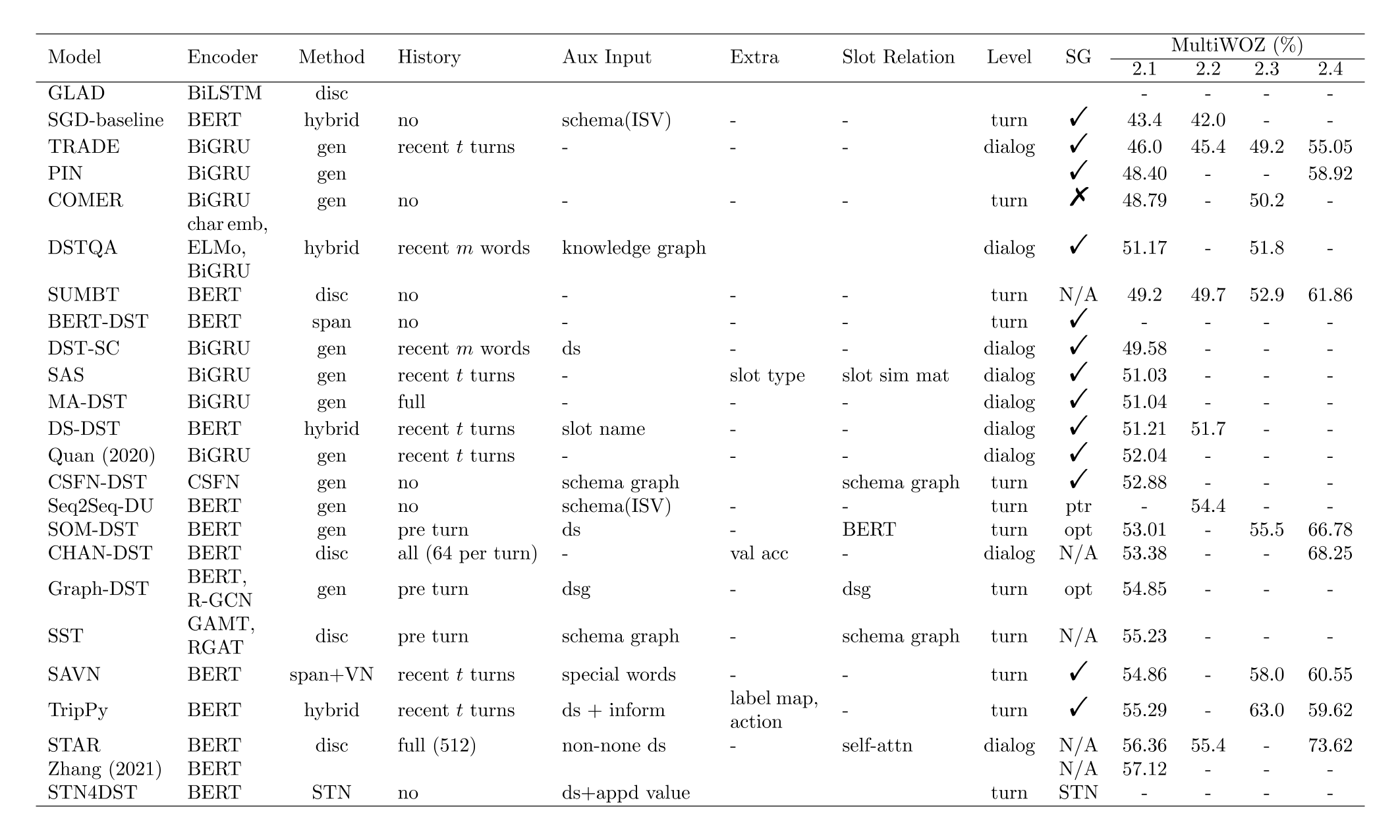
对于这张图在下面进行进一步解释:
问:cls 和 disc 有什么区别?
答:cls 指的是 classification model,disc 指的是 discriminative model。前者只是一个普通的线性分类器,后者指的是计算槽位表征和槽值表征之间的距离。本质上都是分类模型。对于这两个方法,模型的输入都是槽位表征,表征的获取方式类似,主要区别在于 cls 没有槽值表征,而 disc 通过 BERT 或其他特征提取器得到槽值的隐藏状态,我称之为槽值表征。从另一个视角来看,这两个方法几乎相同。试想将分类模型中的权重矩阵的每一行看作一个槽值表征,那么相对于 disc 来说,这些都是随机初始化的表征。所以二者的区别无非就两点:第一,cls 的槽值表征是随机的;第二,cls 多一个 bias。这一点其实在《DST 增强·槽位表征》一节提到了。我认为 disc 的优势在于它的槽值表征具有语义。实验表明,disc 大约好一个点。最后,disc 是个人命名,意味着槽位与槽值之间的判别,其它文献中应该没这种叫法。
问:dialog-level DST 和 history 有关系吗?
答:history 指的是对话历史。dialog-level DST 通常从头开始预测对话状态,如果没有对话历史,那么它自然无法预测前几轮的用户目标。这一点在《DST 分类·根据状态级别分类》中提到了。所以可能就有一种误解,dialog-level 的输入总是包含历史,turn-level DST 总是不包含历史。其实这是无所谓的。对话历史只是辅助信息,turn-level DST 照样可以输入全部的对话历史。
问:Aux Input 和 Extra 有什么区别?
答:Aux Input 代表辅助输入,Extra 指的是额外的信息。Aux Input 可以是图结构的对话状态,可以是槽位描述,也可以是自定义的特殊值。Extra 是与模型无关信息,例如 CHAN-DST 利用了验证集的准确率处理槽位的长尾问题,TripPy 利用 label map 在推理时进行后处理。
DST分类
在进入深度学习时代后,DST 领域涌现了大量模型。本节对多种 DST 方式进行归类整理,详见下图。下面将分别介绍每种类别的相关工作。

联合模型和独立模型
传统 DST 算法的输入是自动语音识别(Automatic Speech Recognition,ASR)以及语音语言理解(Speech Language Understanding,SLU)的输出和以前的系统动作,然后用统计方法更新对话状态(存疑)。由于这三项输入都具有不可避免的误差,因此它会遭受误差传播的影响。Henderson, Thomson, and Young (2014) 舍弃了 ASR、SLU 模块,直接向模型输入自然语言语句以及其它多种特征 (Henderson, Thomson, and Young 2013),并且首次在 DST 领域探索了循环神经网络(Recurrent Neural Network,RNN)。这种将 SLU 和 DST 联合训练的模型被称为联合模型(joint model),反之则称为独立模型(separate model)。Z. Zhang et al. (2020) 也称它们为 word-level DST 和 DA-level DST。在此之后,联合模型几乎成为 DST 领域的通用做法。
根据是否使用本体分类
本体(ontology)枚举了系统中包含的所有槽位及其可能的候选槽值,例如对于槽位“hotel-star”,它可能的候选槽值有 {0, 1, 2, 3, 4, 5}。现存的模型根据是否使用本体可以被大致划分为:基于本体(ontology-based)方式和无本体(ontology-free)方式 (Zhang et al. 2020)。基于本体方式 (Mrkšić et al. 2017; Rastogi, Hakkani-Tür, and Heck 2017; Zhong, Xiong, and Socher 2018; Lee, Lee, and Kim 2019; Shan et al. 2020; Ye et al. 2021) 假定候选槽值已知,然后将 DST 简化为多任务分类任务(multi-task classification task)(Z. Zhang et al. 2020 ch. 2.2)。
然而,基于本体方式的可扩展性非常差。在真实场景中,系统往往需要处理一些不可枚举或者未知的值,例如无穷的日期和周期性增加的音乐名称。由于它们无法被预先定义,因此无法从分类模型的概率空间中获得。如果候选槽值有所改动,则必须重新训练 DST 模型。为了解决这一难题,Xu and Hu (2018) 首次提出使用指针神经网络(Pointer Network,PtrNet) (Vinyals, Fortunato, and Jaitly 2015) 从对话历史中计算值跨度(value span),以此生成无法预先定义的槽值。具体来说,PtrNet 将对话历史作为输入,从而生成两个基于对话历史的概率分布,最后分别取最大值即可得到起始位置和终止位置,即跨度。跨度之内的字符串就是待求的槽值。
无本体方式 (Wu et al. 2019; Ren, Ni, and McAuley 2019; Kumar et al. 2020; Heck et al. 2020; Ouyang et al. 2020; Zhu et al. 2020; Quan and Xiong 2020; Zeng and Nie 2020; Kim et al. 2020; Hu et al. 2020) 彻底舍弃了本体,它们假定槽值不可知。该方式大致可以分为抽取式(extractive)和生成式(generative)。抽取式模型除了上述基于 span 的做法之外,还有一种基于序列标注的做法。本质上二者是类似的。生成式模型将 DST 建模为序列到序列(sequence-to-sequencce,seq2seq)任务,它从预定义的词表中生成单词,解码结束即可获得对应的槽值。这有希望缓解抽取式模型的一个缺点,即槽值依赖于语句的表达,如果语句中具有错别字,那么抽取出的槽值就不合理。不过对于生成式模型的这一优点,据我所知目前还未见到有研究人员讨论、研究过。具有代表性的生成式模型是 Wu et al. (2019) 提出的 TRADE,其基于 PtrNet 的一个变种:Pointer-Gnerator (See, Liu, and Manning 2017)。Pointer-Gnerator 生成的单词既可以来自词表也可以来自上下文。
综上所述,当槽位可分类时,基于本体方式更具有优势;当槽位不可分类时,无本体方式更具有优势。基于这种想法,研究人员开始关注混合方式(hybrid approach)。混合方式 (Goel, Paul, and Hakkani-Tür 2019; Gao et al. 2020; Zhou and Small 2019; Rastogi et al. 2020; Zhang et al. 2020) 假定预先已知槽位是否可分类,然后分别使用基于本体和无本体的方式填充对应槽位。然而,如何确定一个槽位是否可分类仍是一个难题。Rastogi et al. (2020) 提出了一种模式(schema),其规定当候选槽值小于 50 时,将槽位视为可分类;否则视为不可分类。阈值可以根据自己的数据集进行调整。
根据状态级别分类
在基于数据驱动的神经对话状态追踪中,主流的做法是将整个对话历史作为输入,然后在每轮从头预测对话状态。尽管这确保了不同轮次之间的对话状态不会相互干扰,但是冗长的对话历史带来了数据稀疏性(data sparsity)问题 (Zhu et al. 2020),并且过长的输入序列也会使得模型需要花费大量时间执行推理步骤。
为了应对上述问题,有一系列工作 (Kim et al. 2020; Zhu et al. 2020; Zeng and Nie 2020) 使用前一轮的对话状态表示对话历史,并且将对话状态视为一个可选择性覆盖的记忆,然后使用轮级状态(turn state,当前轮预测出的少数槽值对)更新前一轮的对话状态。具体来说,前一轮的对话状态被表示为 \(B_{t-1} = B^1_{t-1} \oplus \cdots \oplus B^{|S|}_{t-1}\),\(|S|\) 是系统中槽位的总量。\(B^i_{t-1} = \text{[SLOT]} \oplus d^i \oplus s^i \oplus v^i_{t-1}\),其中 \(\text{[SLOT]}\) 被期望聚合来自对应三元组的局部信息和来自上下文的全局信息,\(d^i\) 表示第 \(i\) 个三元组中的领域,\(s^i\) 表示第 \(i\) 个三元组中的槽位,\(v^i_{t-1}\) 表示 \(t-1\) 轮中第 \(i\) 个三元组中的槽值,\(\oplus\) 是一个字符串拼接操作。那么模型输入可以被形式化表示为 \(\text{[CLS]} \oplus B_{t-1} \oplus X\),其中 \(X\) 是上下文,一般是前一轮的系统回复和当前轮的用户输入,不过也可以输入更长的上下文。在 \(t\) 轮,模型根据上下文预测轮级状态 \(b_t = \{(s^i_t, v^i_t) | 0 < i < k \ll |S|\}\)。通过某种更新策略,将 \(b_t\) 填入 \(B_{t-1}\),得到 \(B_t\)。
我们将提到的两种做法分别命名为 dialog-level DST 和 turn-level DST (Le, Socher, and Hoi 2020)。在基于数据驱动的神经对话状态追踪中,大部分模型都是 dialog-level DST。
根据是否使用槽位门控分类
待补充。
DST增强
上节介绍了 DST 的各种做法,除了这些之外,还有一些方法可以用于增强 DST 的预测能力。
槽位表征
简单来说,DST 需要追踪所有领域的所有槽位,以在每轮对话过程中获得用户目标。如果将追踪过程视为分类任务,那么 DST 是一个多任务分类任务,而诸如文本分类等任务则是单任务分类任务。也就是说,DST 任务需要为每个槽位都创建一个唯一的分类器。这种做法主要有以下几种缺点。
第一,泛化能力不强。每个领域的每个槽位都具有特定的分类器参数,即使两个槽位相似,一个槽位的分类器也无法处理另一个槽位,比如“飞机-起飞时间”和“火车-出发时间”。第二,分类器无法得到充分训练。由于每个槽位的分类器都是独立的并且任务型对话数据本来就稀少,因此每个分类器只能分到一点训练数据。这正反映了第一点,例如飞机领域只有少量的数据,火车领域反之。我们应该期望“火车-出发时间”这个槽位利用其大量的训练数据从而能够处理“飞机-起飞时间”。第三,可扩展性不高。如果系统加入新槽位,模型必须被重新训练,另外还需要考虑其是否拥有相应训练数据的问题(数据稀缺)。第四,无法并行处理所有槽位。
除了将 DST 建模为分类模型之外,还有人 (Mrkšić et al. 2017) 将其建模为判别式模型,二者的缺点类似。
为了解决上述问题,Rastogi, Hakkani-Tür, and Heck (2017) 共享了所有槽位的参数,这得以充分利用训练数据去训练一个分类器。除此之外,该模型还有一定的泛化能力。由于参数共享机制,它能够处理类似的槽位,例如“餐厅-区域”和“电影院-区域”。在 BERT (Devlin et al. 2019) 被提出后,涌现了大量以 BERT 为编码器的模型 (Chao and Lane 2019),也探索了一些新的编码方式 (Lee, Lee, and Kim 2019; Zhang et al. 2020),具体来说将槽位名称或槽位描述直接追加在上下文的前面或后面。这种编码方式输出的 \(\text{[CLS]}\) 可以看作是某个上下文感知(context-aware)的槽位表征,然后在下游接分类器或直接与候选值一一判别。在预训练时代,使用判别式模型的好处是“槽值”也具有了预训练模型给予的语义,在训练初期槽值向量不再是随机的(与之相对,分类器中的参数是随机的)。然而,这种做法需要让每条上下文与每个槽位进行排列组合,编码效率不高。简单来说,一条上下文需要和 \(S\) 个槽位拼接 \(S\) 次并编码,可以看出上下文被重复编码了 \(S\) 次。此外也没有解决其它缺点。
注:分类器中的权重矩阵可以看作是基于特定槽位的,权重矩阵中的每个权重向量可以看作是槽值表征。分类模型实际上与判别式模型类似,只不过多了一个偏差(bias)。
从最初为每个槽位都分配一个分类器,到共享所有分类器参数,再到利用 BERT 获取上下文感知的槽位表征。这些方法的更替确实使模型表现有了大幅的提升,也体现了以合理方式获取槽位表征和槽值表征的重要性,下图展示了三种方法的区别。然而,上述三种做法都无法并行处理槽位,这对于拥有大量槽位的对话系统来说无疑是场灾难。此外,模型的泛化能力以及可扩展性仍旧不高。以下介绍一些计算槽位表征的方法,对于槽值表征来说比较简单,只需要编码对应槽值即可。

在介绍之前,下图展示了各方法之间的联系以供参考。最简单的做法是编码槽位名称短语 (Wu et al. 2019; Kumar et al. 2020),比如“酒店-名称”,其中编码器可以是任意的神经网络,甚至可以是嵌入层 (Ouyang et al. 2020)。近年,有些工作探索了一种更好的方式,它能使 DST 模型拥有更强的泛化能力和可扩展性,即使用槽位描述初始化槽位表征。比如对于槽位“旅游景点-区域”,它的槽位描述是“旅游景点在城市的哪个区域”。如果某个新加入的槽位或数据量较少的槽位与系统中某些槽位类似(无论是同领域还是不同领域),由于预训练模型为槽位提供了丰富的语义信息,DST 模型理应能够处理该槽位。甚至于系统加入一个全新的领域,比如“磁悬浮列车”,模型利用语义依旧能够处理它。更详细的讨论见《近期的挑战·可扩展性差》一节。

在得到槽位表征之后,比较直接的想法是让其与上下文交互从而获得上下文感知的槽位表征 (Hu et al. 2020; Wang, Guo, and Zhu 2020),我们命名为 slot-token attention。这种做法其实与将槽位名称与上下文拼接进而获取表征的做法(本章第三段)类似,区别是 slot-token attention 的速度略快。Ye et al. (2021) 提出 slot self-attention,在得到槽位表征之后对所有槽位做 self-attention,期望提取到槽位之间的关联(relation)。通常值共享现象比较常见,例如当用户预定餐厅且需要一辆出租车时,“餐厅-预定时间”的值暗示了“出租车-到达时间”。除此之外,一些槽值也具有高度的共现概率 (Ye et al. 2021),例如餐厅名称应该与它提供的食物类型高度相关。关于槽位关联更具体的讨论见下一节。
Kumar et al. (2020) 和 Shan et al. (2020) 使用略微不同的方式获取上下文感知的槽位表征。他们首先使用注意力机制让槽位表征与词向量进行交互,然后再进行上下文级别的交互。具体来说,Kumar et al. (2020) 直接使用嵌入层得到语句和槽位的词向量,然后让二者交互并将结果输入进 RNN 以此得到上下文隐藏状态,最后进行上下文级别的注意力交互。Shan et al. (2020) 使用多个 BERT 分别得到每轮对话的隐藏状态,然后进行词级别的注意力交互并将拼接后的结果输入上下文编码器(Transformer encoder),最后同样进行上下文级别的注意力交互。
上述的 attention 可以自行选择,例如 dot attention,scaled dot-product attention,multi-head attention 等。
槽位关联
在多领域的背景下,一些槽位可能存在关联(relation)。例如两个槽位的值相同(值共享),餐厅名称和食物类型可能有关。近几年有些工作开始探索如何捕获槽位之间的关联。Hu et al. (2020) 使用一个槽位相似度矩阵(slot similarity matrix)实现槽位之间的信息共享,矩阵的取值范围在 \(\{0, 1\}\)。简单来说就是将相似度为 1 的槽位表征相加。他们探索了三种方法创建矩阵,一是计算槽位表征之间的余弦相似度,二是利用 K-means 算法聚类,三是人工构建。实验显示人工构建矩阵的效果反而更差,第一种最好,但是第二种不需要人工调整超参数且结果接近。Ye et al. (2021) 在槽位编码器之上堆叠了多层的 self-attention,以此期望捕获槽位之间的联系。实验表明层数等于 6 时,模型表现最好。
除了注意力机制之外,还有一些工作 (Zhu et al. 2020; Chen et al. 2020; Zeng and Nie 2020) 探索了图神经网络(Graph Neural Network)在提取槽位关联上的应用。他们一般将对话状态表示为图的形式,本文称为对话状态图(dialog state graph)。
其他技巧
long context modeling
Quan and Xiong (2020) 将 \(\text{[usr]}\) 和 \(\text{[sys]}\) 分别放于用户语句和系统回复的首部,以此加强模型区分语句归属谁的能力。实验结果显示,这能提升 1.53%。此外,他们还使用了一个额外的双向语言模型作为辅助任务,结果显示这能提升 2.74%。以上实验基于 TRADE 模型 (Wu et al. 2019)。通过分析,他们发现以上两种做法确实能够增强 DST 建模长对话的能力。
Zhang et al. (2021)
近期的挑战
虽然对话状态追踪任务已经取得了较为不错的进展(截止 2021.04,在 MultiWOZ 2.4 上,基于本体方式达到 73.62% JGA,无本体方式达到 66.78%),但是提出的模型都具有诸多的局限性。Dai et al. (2020) 总结了 DST 现存的一些挑战(本人加入了一些内容),如下所示:

可扩展性差
本节首先通过领域自适应介绍 DST 的可扩展性差主要体现在什么地方,即未知的用户动作和系统动作,然后分别介绍它们以及对应可能的解决办法。
领域自适应
数据驱动的 DST 需要标注数据,其中在每轮应该提供对话状态,因此将一个已经训练好的 DST 迁移到新领域或者将新领域集成到原 DST 中就需要额外的标注数据。领域自适应(domain adaption)是 DST 亟需解决的难题,其关键是如何使模型处理不同领域之间的槽位。不同领域之间可能存在相同、类似甚至完全不同的槽位,例如对于飞机和高铁领域,部分槽位完全相同(出发地、目的地),也有部分槽位类似(飞机的起飞时间和高铁的出发时间);对于电脑和医院领域,它们的大部分槽位都不同。
Rastogi, Hakkani-Tür, and Heck (2017) 首次提出可扩展的多领域 DST,他们主要解决槽值是无穷或动态和模型无法迁移到新领域两个问题。对于前者,使用一个动态的候选值集合 \(C^t_s\),其中 \(t\) 代表轮数,\(s\) 代表具体槽位,同时强制使 \(|C^t_s| \le K\),它们取 \(K\) 为 7。在对话开始,所有槽位的 \(C^0_s\) 都为空。然后,每轮使用以下方式生成候选槽值:1)将用户提到的所有值加入 \(C^t_s\);2)将系统提到的所有值加入 \(C^t_s\);3)按照分数逆序排序,用 \(C^{t-1}_{s,i}\) 扩展 \(C^t_s\)。那么,如何抽取语句中的值以及如何获得分数呢?借用 multi-domain SLU 的工作,即序列标注任务。注意,他们没有联合训练 SLU 和 DST 两个任务,只是借用。\(K = 7\) 可能是考虑到在一场对话中对话状态中的槽值最多也没几个。对于后者,它们共享了所有槽位的参数,这使得模型能够处理未知但与已知槽位类似的槽位。实验证明在评估 Sim-M 时,使用 Sim-R 训练比使用 DSTC2 要好,因为 Sim-M 和 Sim-R 有三个槽位(date,time,area)完全相同。下图展示了一个槽位迁移的例子,模型可以处理名称相同的槽位。另外,spanPtr (Xu and Hu 2018) 的思想显然与使用 SLU 抽取槽值的做法类似。事实上,Xu and Hu (2018) 确实参考了他们的做法。

Rastogi, Gupta, and Hakkani-Tur (2018) 改进了上述做法,建立联合模型,同时还预测了用户意图。此外,DST 在训练时使用的是 SLU 所用的真实标签,而在推理时,却使用 SLU 标注的字符串。为此,他们还探索了 scheduled sampling 技术在 SLU 和 DST 联合训练上的应用。然而,由于该做法需要使用模式中的元素,例如作为标签的意图和槽位,因此仍旧无法被零样本泛化到新领域或 API (Kim et al. 2019 ch. 5.1)。
综上所述,DST 的领域自适应需要解决以下三点:未知的意图、未知的槽位以及未知的槽值,可以被概括为未知的用户动作。下节将对其进一步介绍,并讨论一些有希望解决该难题的技术。
如何处理未知的用户动作
对话动作由意图、槽位和槽值组成,表示为 intent(slot, value),例如 inform(hotel-pricerange, expensive)。当对话动作的主体是用户时,即用户动作,三项都有可能出现未知的情况。如果系统没有考虑用户的意图,那么它可能答非所问 (Dai et al. 2020 ch. 2.1.1)。当系统增加新的服务时,例如增加一项外卖订餐服务,其中必然出现新的领域以及新的槽位。此时,模型必须被重新训练,并且可能还需要新的标注数据。未知槽值现象出现得更频繁,且不说系统更新。当槽值是不可枚举或者周期性增加时,系统就难以处理它们,例如日期、地点、音乐名称等。
为了处理未知的槽位,Bapna et al. (2017) 首次提出使用槽位描述表示槽位,利用 BiLSTM 编码现存或新槽位的自然语言描述以此得到槽位表征(具体实验中,他们只使用了描述的词向量平均)。之后,他们利用该表征进行序列标注以此得到槽值。这是一个槽填充任务,是 SLU 的三大子任务之一。该思想来源于问答(Question Answering,QA)和机器阅读(Machine Reading)任务。给定一个问题,模型从上下文中找出答案。后来,Rastogi et al. (2020) 提出的模式引导范式(schema-guided paradigm)就是对其的扩展。
为了处理未知的槽值,Xu and Hu (2018) 首次提出使用指针神经网络(Pointer Network,PtrNet)直接从对话历史中抽取槽值。这一部分已经在《DST 分类·根据是否使用本体分类》一节中讨论过,不再赘述。
未知意图的处理,可以使用类似槽位描述的思想。目前没有看到这一方面的研究。
除了上述利用自然语言描述的思想之外,近几年还有些工作使用了 few-shot learning 或 zero-shot learning。
如何处理未知的系统动作
主要由 DPL 模块处理。
数据稀缺
待补充。
计算复杂度高
待补充。这方面的工作不是很多。
总结
对话状态追踪(dialogue state tracking,DST)在任务型对话系统起到了承上启下的作用。它的做法多样,主要可以划分为:基于本体方式,无本体方式和混合方式。基于本体方式假定槽值已知,无本体方式假定槽值不可知,混合方式结合了上述两种方式的优点。无论是哪种方式,它们都需要一个预定义的本体,其中定义了所有的领域、槽位和槽值,还需要大量的数据供其训练。此外,DST 任务的目的在于使用预测的槽值填充所有槽位,现有模型很难并行处理所有槽位。综上所述,目前 DST 面临的挑战有:一,泛化能力不强;二,可扩展性不高;三,数据稀缺;四,训练、推理速度缓慢。
除此之外,本人再补充以下几点:
- 没有文本纠错能力:当 DST 利用指针神经网络抽取出用户语句中的实体时,如果用户拼写错误,模型无法感知到这一点。
- 语言理解能力依旧低下:任务型对话数据集一般由人工构建,而不是来自真实应用场景下的数据。当系统询问“这边找到挺多房间的,请问你需要哪种类型?”,用户常表达类似于“帮我找一间标准型房间吧”、“帮我找一间标准间吧,价格要在 300 元左右”的语句。而在真实场景中,用户会表达“标间”、“标间,要 300 左右的”。
- 没有语句补全能力:同上。
- 误差累积:DST 任务有太多子任务,比如槽位填充、意图识别、领域识别、请求槽位预测。如果加上上述的内容,则还需要文本纠错任务和语句补全任务。
语音语言理解
待补充。
参考文献
Bapna, Ankur, Gokhan Tür, Dilek Hakkani-Tür, and Larry Heck. 2017. “Towards Zero-Shot Frame Semantic Parsing for Domain Scaling.” In Proc. Interspeech 2017, 2476–80. https://doi.org/10.21437/Interspeech.2017-518.
Budzianowski, Pawel, Tsung-Hsien Wen, Bo-Hsiang Tseng, Inigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašić. 2018. “Multiwoz-a Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling.” arXiv Preprint arXiv:1810.00278.
Chao, Guan-Lin, and Ian Lane. 2019. “BERT-Dst: Scalable End-to-End Dialogue State Tracking with Bidirectional Encoder Representations from Transformer,” July. http://arxiv.org/pdf/1907.03040v1.
Chen, Lu, Boer Lv, Chi Wang, Su Zhu, Bowen Tan, and Kai Yu. 2020. “Schema-Guided Multi-Domain Dialogue State Tracking with Graph Attention Neural Networks.” Proceedings of the AAAI Conference on Artificial Intelligence 34 (05). Association for the Advancement of Artificial Intelligence (AAAI): 7521–8. https://doi.org/10.1609/aaai.v34i05.6250.
Dai, Yinpei, Huihua Yu, Yixuan Jiang, Chengguang Tang, Yongbin Li, and Jian Sun. 2020. “A Survey on Dialog Management: Recent Advances and Challenges.” arXiv Preprint arXiv:2005.02233.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–86. Minneapolis, Minnesota: Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1423.
Eric, Mihail, Rahul Goel, Shachi Paul, Adarsh Kumar, Abhishek Sethi, Peter Ku, Anuj Kumar Goyal, Sanchit Agarwal, Shuyang Gao, and Dilek Hakkani-Tur. 2019. “MultiWOZ 2.1: A Consolidated Multi-Domain Dialogue Dataset with State Corrections and State Tracking Baselines.” arXiv Preprint arXiv:1907.01669.
Gao, Shuyang, Sanchit Agarwal, Di Jin, Tagyoung Chung, and Dilek Hakkani-Tur. 2020. “From Machine Reading Comprehension to Dialogue State Tracking: Bridging the Gap.” In Proceedings of the 2nd Workshop on Natural Language Processing for Conversational Ai, 79–89. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.nlp4convai-1.10.
Goel, Rahul, Shachi Paul, and Dilek Hakkani-Tür. 2019. “Hyst: A Hybrid Approach for Flexible and Accurate Dialogue State Tracking.” arXiv Preprint arXiv:1907.00883.
Han, Ting, Ximing Liu, Ryuichi Takanobu, Yixin Lian, Chongxuan Huang, Wei Peng, and Minlie Huang. 2020. “MultiWOZ 2.3: A Multi-Domain Task-Oriented Dataset Enhanced with Annotation Corrections and Co-Reference Annotation.” arXiv Preprint arXiv:2010.05594.
Heck, Michael, Carel van Niekerk, Nurul Lubis, Christian Geishauser, Hsien-Chin Lin, Marco Moresi, and Milica Gasic. 2020. “TripPy: A Triple Copy Strategy for Value Independent Neural Dialog State Tracking.” In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 35–44. 1st virtual meeting: Association for Computational Linguistics. https://www.aclweb.org/anthology/2020.sigdial-1.4.
Henderson, Matthew, Blaise Thomson, and Steve Young. 2013. “Deep Neural Network Approach for the Dialog State Tracking Challenge.” In Proceedings of the SIGDIAL 2013 Conference, 467–71. Metz, France: Association for Computational Linguistics. https://www.aclweb.org/anthology/W13-4073.
———. 2014. “Word-Based Dialog State Tracking with Recurrent Neural Networks.” In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (Sigdial), 292–99.
Hu, Jiaying, Yan Yang, Chencai Chen, Liang He, and Zhou Yu. 2020. “SAS: Dialogue State Tracking via Slot Attention and Slot Information Sharing.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 6366–75. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.567.
Kim, Seokhwan, Michel Galley, Chulaka Gunasekara, Sungjin Lee, Adam Atkinson, Baolin Peng, Hannes Schulz, et al. 2019. “The Eighth Dialog System Technology Challenge.” arXiv Preprint arXiv:1911.06394.
Kim, Sungdong, Sohee Yang, Gyuwan Kim, and Sang-Woo Lee. 2020. “Efficient Dialogue State Tracking by Selectively Overwriting Memory.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 567–82. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.53.
Kumar, Adarsh, Peter Ku, Anuj Goyal, Angeliki Metallinou, and Dilek Hakkani-Tur. 2020. “MA-Dst: Multi-Attention-Based Scalable Dialog State Tracking.” In Proceedings of the Aaai Conference on Artificial Intelligence, 34:8107–14. 05.
Le, Hung, Richard Socher, and Steven C.H. Hoi. 2020. “Non-Autoregressive Dialog State Tracking.” In International Conference on Learning Representations. https://openreview.net/forum?id=H1e_cC4twS.
Lee, Hwaran, Jinsik Lee, and Tae-Yoon Kim. 2019. “SUMBT: Slot-Utterance Matching for Universal and Scalable Belief Tracking.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 5478–83. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1546.
López-Cózar, Ramón, Zoraida Callejas, David Griol, and José F. Quesada. 2014. “Review of Spoken Dialogue Systems.” Loquens 1 (2). Editorial CSIC: e012. https://doi.org/10.3989/loquens.2014.012.
Mrkšić, Nikola, Diarmuid Ó Séaghdha, Tsung-Hsien Wen, Blaise Thomson, and Steve Young. 2017. “Neural Belief Tracker: Data-Driven Dialogue State Tracking.” In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1777–88.
Ni, Jinjie, Tom Young, Vlad Pandelea, Fuzhao Xue, Vinay Adiga, and Erik Cambria. 2021. “Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey.”
Ouyang, Yawen, Moxin Chen, Xinyu Dai, Yinggong Zhao, Shujian Huang, and Jiajun Chen. 2020. “Dialogue State Tracking with Explicit Slot Connection Modeling.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 34–40. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.5.
Quan, Jun, and Deyi Xiong. 2020. “Modeling Long Context for Task-Oriented Dialogue State Generation.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 7119–24. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.637.
Quan, Jun, Shian Zhang, Qian Cao, Zizhong Li, and Deyi Xiong. 2020. “RiSAWOZ: A Large-Scale Multi-Domain Wizard-of-Oz Dataset with Rich Semantic Annotations for Task-Oriented Dialogue Modeling.” In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-main.67.
Ramadan, Osman, Pawel Budzianowski, and Milica Gašić. 2018. “Large-Scale Multi-Domain Belief Tracking with Knowledge Sharing.” arXiv Preprint arXiv:1807.06517.
Rastogi, Abhinav, Raghav Gupta, and Dilek Hakkani-Tur. 2018. “Multi-Task Learning for Joint Language Understanding and Dialogue State Tracking.” In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, 376–84. Melbourne, Australia: Association for Computational Linguistics. https://doi.org/10.18653/v1/W18-5045.
Rastogi, Abhinav, Dilek Hakkani-Tür, and Larry Heck. 2017. “Scalable Multi-Domain Dialogue State Tracking.” In 2017 Ieee Automatic Speech Recognition and Understanding Workshop (Asru), 561–68. IEEE. https://doi.org/10.1109/ASRU.2017.8268986.
Rastogi, Abhinav, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, and Pranav Khaitan. 2020. “Towards Scalable Multi-Domain Conversational Agents: The Schema-Guided Dialogue Dataset.” Proceedings of the AAAI Conference on Artificial Intelligence 34 (05): 8689–96. https://doi.org/10.1609/aaai.v34i05.6394.
Ren, Liliang, Jianmo Ni, and Julian McAuley. 2019. “Scalable and Accurate Dialogue State Tracking via Hierarchical Sequence Generation.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics. https://doi.org/10.18653/v1/d19-1196.
See, Abigail, Peter J. Liu, and Christopher D. Manning. 2017. “Get to the Point: Summarization with Pointer-Generator Networks.” In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics. https://doi.org/10.18653/v1/p17-1099.
Shan, Yong, Zekang Li, Jinchao Zhang, Fandong Meng, Yang Feng, Cheng Niu, and Jie Zhou. 2020. “A Contextual Hierarchical Attention Network with Adaptive Objective for Dialogue State Tracking.” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 6322–33. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.563.
Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. 2015. “Pointer Networks.” In Advances in Neural Information Processing Systems, edited by C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett. Vol. 28. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2015/file/29921001f2f04bd3baee84a12e98098f-Paper.pdf.
Wang, Yexiang, Yi Guo, and Siqi Zhu. 2020. “Slot Attention with Value Normalization for Multi-Domain Dialogue State Tracking.” In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (Emnlp), 3019–28. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-main.243.
Wu, Chien-Sheng, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher, and Pascale Fung. 2019. “Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 808–19. Florence, Italy: Association for Computational Linguistics. https://doi.org/10.18653/v1/P19-1078.
Xu, Puyang, and Qi Hu. 2018. “An End-to-End Approach for Handling Unknown Slot Values in Dialogue State Tracking.” In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1448–57. Melbourne, Australia: Association for Computational Linguistics. https://doi.org/10.18653/v1/P18-1134.
Ye, Fanghua, Jarana Manotumruksa, and Emine Yilmaz. 2021. “MultiWOZ 2.4: A Multi-Domain Task-Oriented Dialogue Dataset with Essential Annotation Corrections to Improve State Tracking Evaluation.” arXiv Preprint arXiv:2104.00773.
Ye, Fanghua, Jarana Manotumruksa, Qiang Zhang, Shenghui Li, and Emine Yilmaz. 2021. “Slot Self-Attentive Dialogue State Tracking.” In Proceedings of the Web Conference 2021, 1598–1608. WWW ’21. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3442381.3449939.
Zang, Xiaoxue, Abhinav Rastogi, Srinivas Sunkara, Raghav Gupta, Jianguo Zhang, and Jindong Chen. 2020. “Multiwoz 2.2: A Dialogue Dataset with Additional Annotation Corrections and State Tracking Baselines.” arXiv Preprint arXiv:2007.12720.
Zeng, Yan, and Jian-Yun Nie. 2020. “Multi-Domain Dialogue State Tracking Based on State Graph.” arXiv Preprint arXiv:2010.11137.
Zhang, Jianguo, Kazuma Hashimoto, Chien-Sheng Wu, Yao Wang, Philip Yu, Richard Socher, and Caiming Xiong. 2020. “Find or Classify? Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking.” In Proceedings of the Ninth Joint Conference on Lexical and Computational Semantics, 154–67. Barcelona, Spain (Online): Association for Computational Linguistics. https://www.aclweb.org/anthology/2020.starsem-1.17.
Zhang, Ye, Yuan Cao, Mahdis Mahdieh, Jeffrey Zhao, and Yonghui Wu. 2021. “Improving Longer-Range Dialogue State Tracking,” February. http://arxiv.org/pdf/2103.00109v2.
Zhang, Zheng, Ryuichi Takanobu, Qi Zhu, Minlie Huang, and Xiaoyan Zhu. 2020. “Recent Advances and Challenges in Task-Oriented Dialog Systems.” Science China Technological Sciences. Springer, 1–17.
Zhong, Victor, Caiming Xiong, and Richard Socher. 2018. “Global-Locally Self-Attentive Dialogue State Tracker.” arXiv Preprint arXiv:1805.09655.
Zhou, Li, and Kevin Small. 2019. “Multi-Domain Dialogue State Tracking as Dynamic Knowledge Graph Enhanced Question Answering,” November. https://arxiv.org/pdf/1911.06192.pdf.
Zhu, Su, Jieyu Li, Lu Chen, and Kai Yu. 2020. “Efficient Context and Schema Fusion Networks for Multi-Domain Dialogue State Tracking.” In Findings of the Association for Computational Linguistics: EMNLP 2020, 766–81. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.findings-emnlp.68.
