知识图谱描述
知识图谱是一种新型的数据库,是一种基于图的数据结构。每个结点表示现实世界中存在的“实体”,每条边为实体与实体之间的“关系”。以下为知识图谱的几点作用: - 从“关系”分析问题 - 把不同种类的信息连接在一起 - 一个关系网络
学习知识图谱首先得掌握以下几种技能: 1. 基础知识:自然语言处理、图数据库操作知识、基本编程能力:Python、SQL; 2. 领域知识:知识图谱构建方法、知识图谱推理方法; 3. 行业知识
知识图谱的构建步骤
- 数据收集(持续收集与更新)(关键词抽取、命名体识别、关系抽取、事件抽取)
- 原始数据,通常可能是一篇文章
- 爬虫技术
- 垂直爬虫
- 搜索引擎相关的爬虫
- 爬虫技术
- 语料数据,通常词库,词典,同义词
- 开源的第三方知识图谱,例如搜狗人物关系图
- 开源的训练好的词向量(word2vec)模型,tfidf
- 原始数据,通常可能是一篇文章
- 图谱设计
- 知识清洗
- 实体消歧
- 实体统一
- 知识融合(实体链接)
- 实体与关系的融合
- 实体扩充(融合外部知识图谱或者数据)(知识合并)
- 知识存储-图数据库
知识图谱的架构与设计
略
知识源数据的获取
略。可以使用爬虫等技术,或者直接网上搜现成的数据。
信息抽取
包括关键词抽取、命名体识别、关系抽取,事件抽取等技术。
关键词抽取
分词
分类算法中的流程: 分词-->(自然语言处理,与,知识,图谱,知识图谱)-->去停词-->(自然语言处理,知识,图谱,知识图谱)-->建立索引-->(1,2,3,432,66)-->one hot-->word2vec-->
语料库
jieba 分词同时基于一些语料库和手写的规则(如隐马尔科夫模型)。 如果想要加入自己的语料库可以使用下面的代码,语料库的格式可在 github jieba 上找到。 1
2
3jieba.load_userdict('/home/python/dictionary.txt')
seg_list = jieba.cut(text, cut_all=True)
print(' '.join(seg_list))
- 词库
- 医药知识图谱
- 语料库(网上有现成的,不用自己爬,如:医药行业专业词典)
- 医院的名称
- 疾病的名称
- 语料库(网上有现成的,不用自己爬,如:医药行业专业词典)
- 医药知识图谱
文本特征提取
文本数据的表示模型: - 布尔模型(boolean model) - 向量空间模型(vector space model) - 概率模型(probabilistic model) - 图空间模型(graph space model)等
以下为几种主要的模型,它们的目标都是:建立文档的向量(矩阵)模型。加粗代表是现在常用的模型 1. TF-IDF 2. LDA 3. LSA/LSI 4. Word2Vec 5. one-hot 6. BERT 7. ...
TF-IDF
TF:词频 IDF:逆文档频率。 权重 = TF * IDF TF-IDF 可能会漏掉一些词。比如一篇文章只出现一次“周杰伦”,但是它已经表示了这篇文章的主旨。可是 TF-IDF 无法为该词分配较高的权重。 另外 jieba 中其实可以直接使用 TF-IDF。导入jieba.analyse即可使用。(TF-IDF 其实就是提取句子的标签) 1
2import jieba.analyse as ja
ja.extract_tags(sentence, topK=3,withWeight=False, allowPOS=())
word2vec
TF-IDF 只考虑单个文字,忽略了句子中的上下文信息。而word2vec 考虑了上下文,输入值为某个单词的前几个单词、后几个单词和其本身。 word2vec 现成的工具包有:1)gensim;2)tensorflow;3)keras。 另外 QA 系统等应用可能不适合使用 word2vec 训练出来的单词。因为它训练出来的词向量没有捕获到太多的上下文信息。众所众知,QA 系统和对话系统等应用需要经常使用到很多上下文信息。
命名体识别——NER
所谓的命名体(named entity)就是人名、机构名、地名以及其他所有以名称为标识的实体。更广泛的实体还包括数字、日期、货币、地址等等。 难点:1)同义词、歧义词等;2)未登录词判定。 一般流程:1)基于规则的方法;2)基于模型的方法,常见的序列标注模型包括 HMM(Hidden Markov Model)、CRF(Conditional random field)、RNN。不过虽然基于模型的方法技术比较新颖,但是由于太过复杂以及太难解释,所以公司还是用基于规则的方法比较多。
序列标注
- 基于HMM
- 基于CRF
上课的时候没听明白。
- 基于RNN 要做命名体识别,首先要做序列标注的任务。目前有以下几种公认的标注体系:
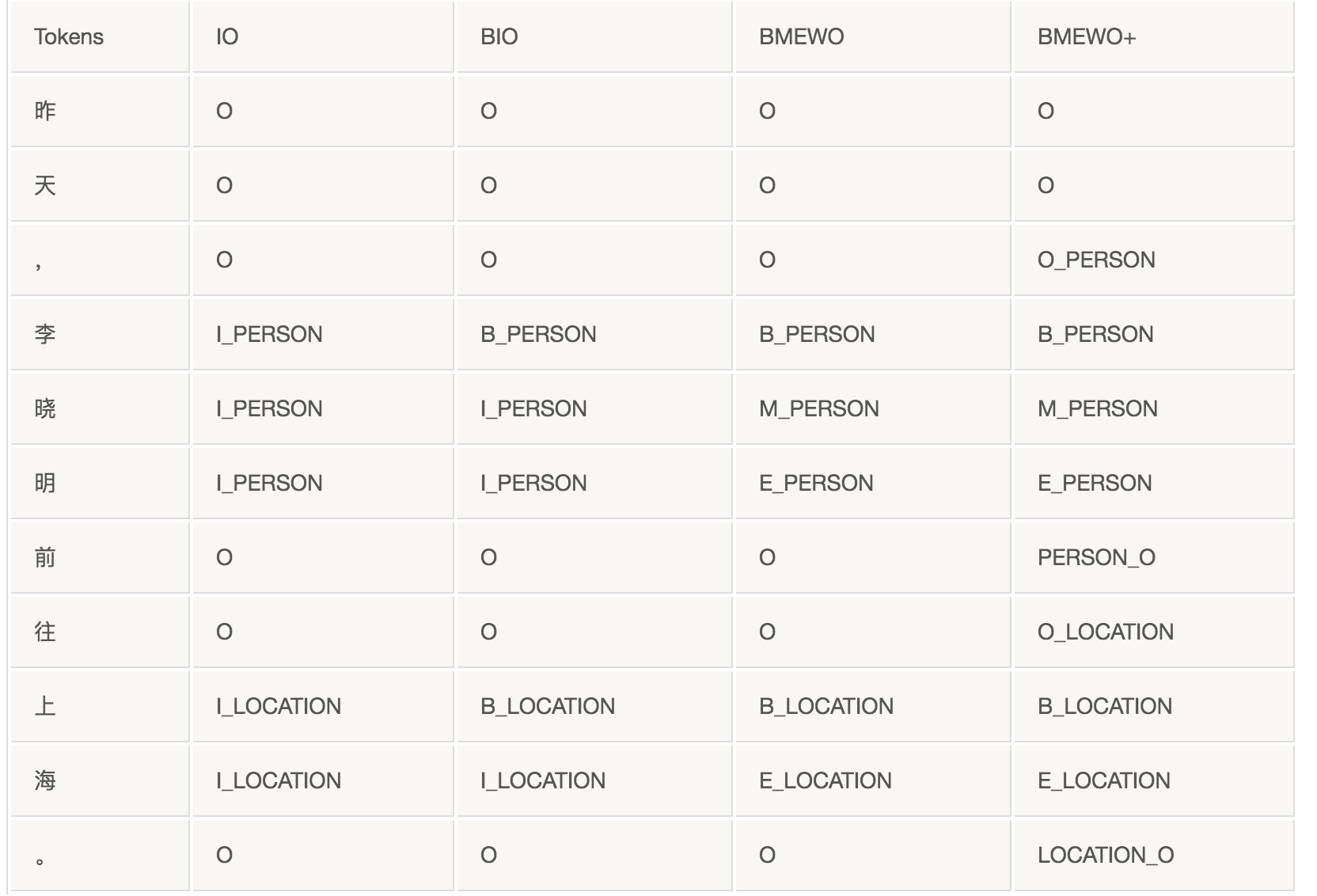
关系抽取(特征工程)
- 文本特征提取,采用 tf-idf
- 关键字抽取,比如转让,收购,整合等等
- 句法特征提取,主要是与核心词之间的关系,包括企业实体本身和前后词与核心词之间的关系,距离等。即抽取(实体,关系,实体)三要素特征
- 依存句法分析
- 依存树,demo
- CCG
- 分类器
- 依存句法分析
- 如果使用 NN 训练,可以拼接三要素和 tf-idf 特征
事件抽取
略,培训中未提到,估计跟关系抽取差不多。
知识融合
实体链接
实体统一/实体对齐
注:另一种说法是实体统一和实体对齐并不是同一件事。此处姑且当它们是同一件事。 对同一实体具有多个名称的情况进行实体统一,将多个名称统一替换成一个命名实体。比如,“河北银行股份有限公司”和“河北银行”可以统一成“河北银行”。 大致来说这个应用是使用规则来做实体统一。目前(2019 年 7 月)来说,基于规则的做法大概能解决 70% 左右的问题。还可以使用余弦相似度,分类等算法进行融合使用。 - 分离出地名,比如河北,北京 - 去除后缀,比如有限公司,集团 - 提取经营范围,比如医疗,化学 - 剩余部分为中间字段 - 最后选择以上四个部分的某些部分进行拼接,成为一个唯一的命名实体,如果有中间字段,则仅使用中间字段即可,并对某些特殊的经营范围做补充,比如银行;否则,优先使用地名加经营范围,其次是地名加后缀。
更新命名体:在做完实体统一之后,将原数据中的实体进行替换即可。
实体消歧
与实体统一不同。实体统一是将两个不一样名称的实体统一起来,而实体消歧是将同一个名称的实体在不同语境下区分开来,比如:苹果在不同的语境下分别有水果和手机的意思。 中文的不怎么好做,主要运用规则。
知识合并
知识加工
知识存储与检索
知识应用
汉语处理的难点

NLP 工具包
略。详见此博客
项目实战
以上为知识图谱的大致概述,以下以几个例子大致地将构建步骤串联起来。首先给出知识图谱的总结思维导图,可以按照图中的内容自行对应查找知识点。思维导图的阅读顺序是从上至下,从右至左。 概述/知识图谱总结.png)
医疗命名体识别
项目地址,使用了基于字向量的四层双向 LSTM 与 CRF 模型的网络。 本项目大致使用了信息抽取->命名体识别的技术。项目中有一个名为 data_origin 的文件夹,其结构为: 1
2
3
4
5
6
7
8data_origin
├─一般项目
│ ├─一般项目-1.txt
│ ├─一般项目-1.txtoriginal.txt
│ └─。。。
├─出院情况
├─病史特点
└─诊疗经过概述/原始数据.jpg)
概述/人工标注后的数据.jpg)
以上的数据为项目的原数据(那个由人工标注过的数据也算原数据),我们需要使用一套标注体系(本项目使用 BIO 体系)来将原数据处理一下,以下是处理结果。 概述/使用%20BIO%20标注后的数据.jpg)
你可能会疑惑 DISEASE-* 之类的东西是什么意思,以及它是怎么出来的。其实十分简单,如下所示,都是预先定义好的。以 B 结尾,代表一个命名体的开始,以 I 结尾,代表一个命名体的结束。而产生数据的过程也只是写死的一套逻辑,使用 if else 进行判断罢了。 概述/标签字典.jpg)
训练之前的准备工作
- 定义标签
- 人工将数据一条一条地标注命名体、起始位置以及标签
- 选择一套标注体系
- 将每一份原数据使用标注体系处理后,存入一份文件
训练
代码中以 ['。','?','!','!','?'] 符号作为一份病历的结束。然后将训练数据重新拆分成多分训练样本。我倒是认为在原数据处理完毕合并时,就做一些处理不行吗?如果以那些符号作为判断条件,可能有些不太准。 1. 加载字向量; 2. 以 ['。','?','!','!','?'] 符号作为一份病历的结束,重新切分数据为多份训练样本; 3. 每一个字都有一个标注,比如训练样本:[感, 染, 风, 寒]和标注:[CHECK-B, CHECK-I, DISEASE-B, DISEASE-I]--转换为-->[32, 8454, 676, 934]和[7, 8, 10, 9]; 4. 程序定义有 150 个时间步,第一层 BiLSTM 为 128 维,第二层的 BiLSTM 为 64 维,各层之间的 Dropout 取 0.5; 5. 将训练样本输入 RNN,RNN 的输出输入 CRF,CRF 输出一个 11 维的向量,即每一个字都会输出一个 11 维的向量。所以可以看做是一个 11 元分类模型,即判断一个字属于哪一类的标注,也就是序列标注的含义——为字标注属性; 6. 训练结束,就完成了一个序列标注模型。
总结
此项目实现了命名体识别的功能,使用了 LSTM 以及 CRF 的技术,原数据采用了人工标注的处理方式,原数据转为训练样本采用了规则模版的方式。总的来说,没有太大难度。对于此项目,我们需要理解 LSTM 和 CRF 的算法,整个过程的难点就在人工标注上,费时费力。
中文人物关系知识图谱
项目地址。此项目代码结构有点复杂,涉及了很多爬虫,我对爬虫不是很了解。
总结
此项目实现了关系抽取的功能,具体使用了什么技术未知。
判断两个企业实体是否存在投资关系
项目地址。
总结
此项目实现了关系抽取和实体统一的功能,基本上使用了人工模版去判断两个企业是否统一。是否存在投资关系也是用规则判断的。
金融问答项目
此项目(实验21-1-FinancialKGQA)实现了一个简单的金融问答项目,前提项目为实验19-neo4j构建简单的金融知识图谱,旨在使用爬虫技术构建一个金融知识图谱。数据和代码已经由 2019.6.27 普开知识图谱培训机构提供。
总结
从下图可以看出,只是简单的关键词匹配。然后通过 neo4j 的 CQL 语句进行查询。 概述/金融问答示例代码.jpg)
