问答系统
知识图谱问答系统概述
现在的搜索引擎工作流程是输入要搜索的内容,搜索引擎返回一大堆内容,供你自己选择。 问答系统是下一代的搜索引擎的基本形态。 > 以直接而准确的方式回答用户自然语言提问的自动问答系统将构成下一代搜索引擎的基本形态。
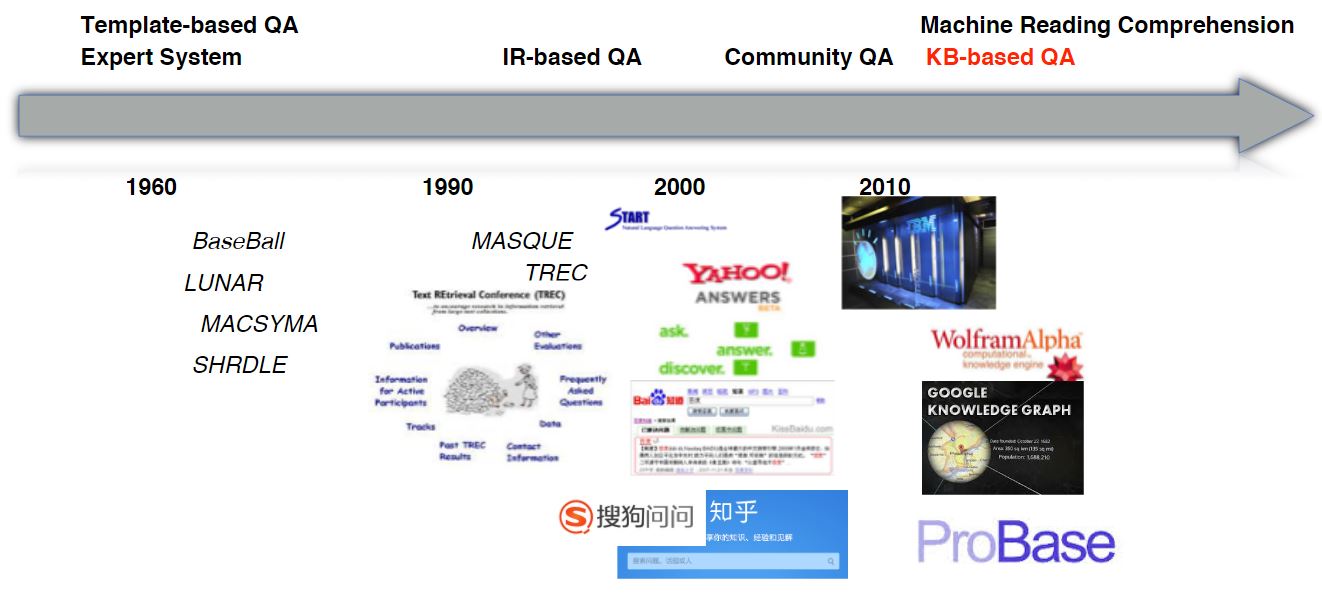
下图展示问答系统在近几十年的发展历史。 1. 1960 年的问答系统属于专家系统(模版系统) 2. 1990 - 2000 年的问答系统属于基于信息检索的 QA 系统 3. 2000 - 2010 年的问答系统属于社区 QA 系统 4. 2011 年之后的问答系统属于基于知识图谱的 QA 系统
分类
问答系统的分类(或者说三个阶段): 1. IR-based QA:基于关键词匹配 + 信息抽取,任然是基于浅层语义分析 2. Community QA:依赖于网民贡献,问答过程任然依赖于关键词检索技术 3. KB-based QA:Knowledge Base,例如:WolfframAlpha
根据问答形式分类: 1. 一问一答:字面意思,也是演讲的主题 2. 交互式问答:就是进行连续的复杂的问答 3. 阅读理解
KB-QA 现在只能解决事实性的问题,无法解决: 1. 怎么去天安门 2. 西红柿炒鸡蛋怎么做等提问
某公司(在会议上没听清,可能是一个公司)只有 5% 的问题能用 KB-QA 解决。
什么是知识图谱
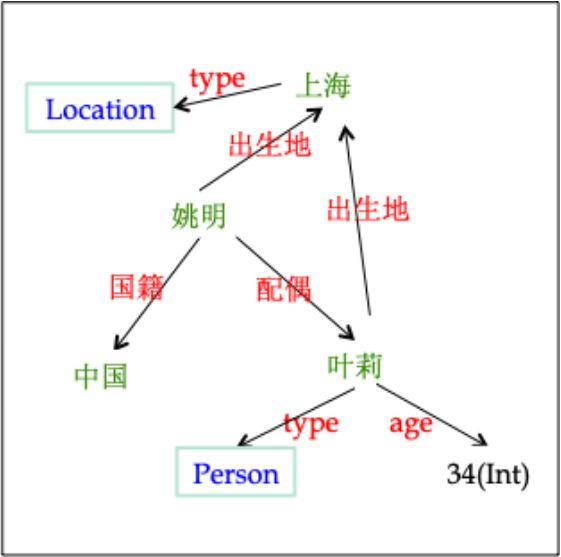
一个简单的例子
知识图谱基本架构
图中三元组中的 Ent1、Ent2 等指的是 entity。entity 可以在架构中选取,比如将 concept 作为 entity 或者将 instance 作为 entity。 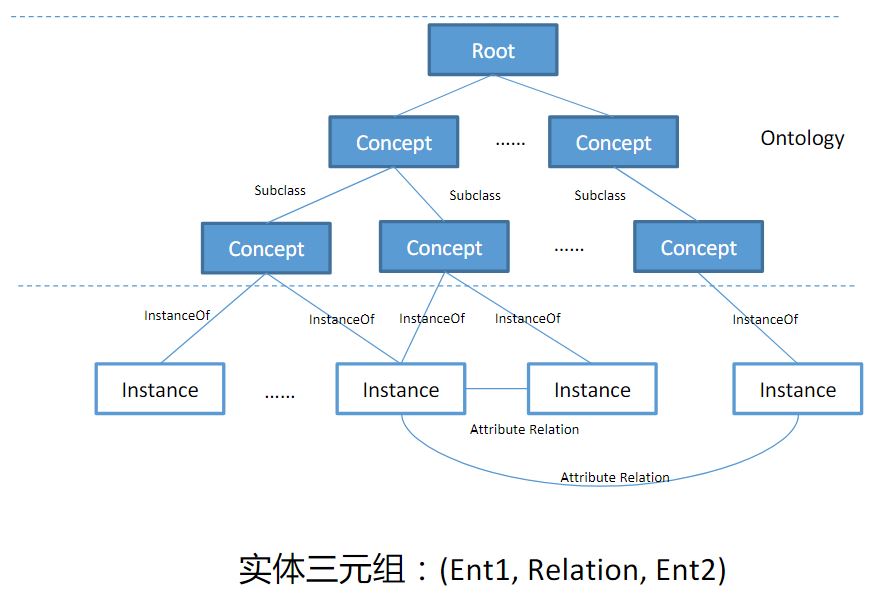
运用知识图谱问答
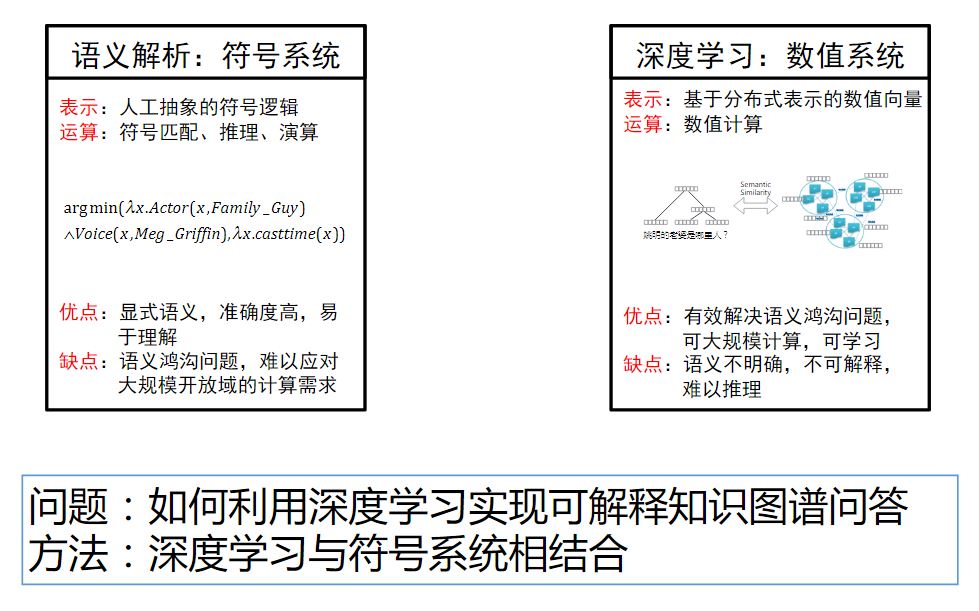
语义如何表示是其中的一个问题: 1. 使用符号表示的形式(传统方法) 2. 使用分布式表示方法
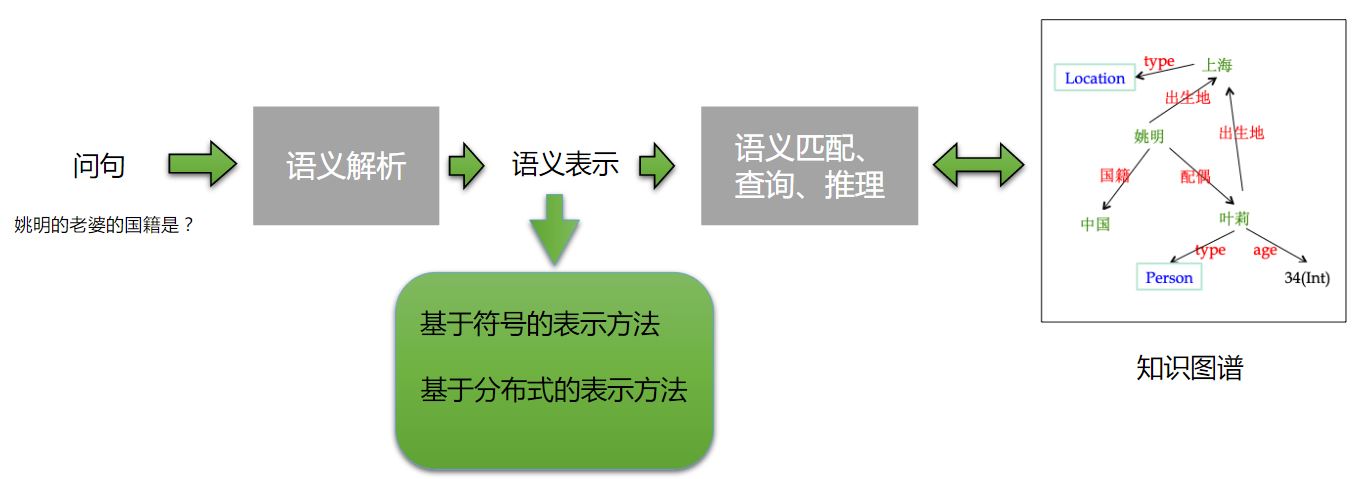
知识图谱问答的两类方法(根据技术路线分)
- 语义解析(Semantic Parsing):问句转换成形式化的查询语句,进行结构化查询得到答案
- 语义检索(Answer Retrieval & Ranking):简单的搜索得到候选答案,利用问句和候选答案的匹配程度(特征)抽取答案
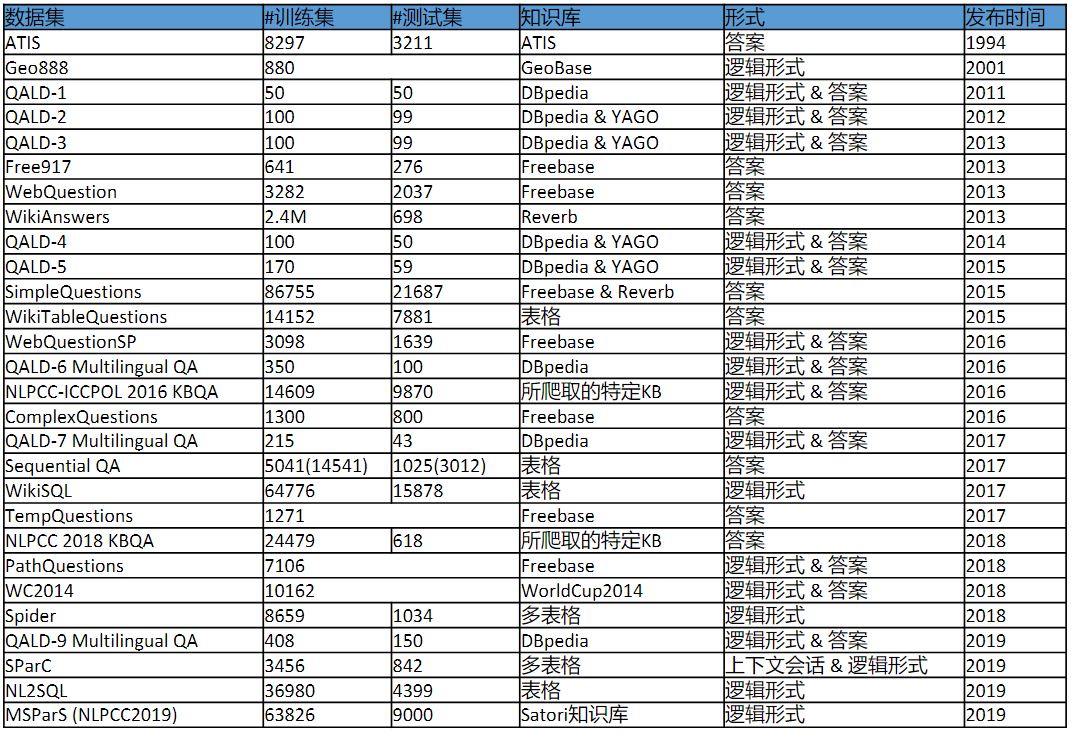
公开的评测数据集
 例如: \[
\text{图数据结构}
\begin{cases}
QALD \\
WebQuestions \\
Simple Question\\
\end{cases}\\
\text{表数据结构}
\begin{cases}
WikiSQL & \text{一个表} \\
Spider & \text{多个表} \\
\end{cases}
\]
例如: \[
\text{图数据结构}
\begin{cases}
QALD \\
WebQuestions \\
Simple Question\\
\end{cases}\\
\text{表数据结构}
\begin{cases}
WikiSQL & \text{一个表} \\
Spider & \text{多个表} \\
\end{cases}
\]
知识图谱问答基于的几种方法
- 基于符号语义解析的知识图谱问答
- 语义表示(lambda 验算,DCS Tree)
- 语义解析方法(CCG)
- 还有许多语义解析方法,略
- 基于语义检索的知识图谱问答
- 基于显示特征的知识检索
- 基于端到端的知识图谱问答
- 基于神经符号计算的知识图谱问答
- 基于序列学习的解析方法
- 基于动作序列的解析方法
- 基于对战神经网络的端到端问答方法
基于符号语义解析的知识图谱问答
两种技术的具体实现过程略过,对比如下图: 
基于语义检索的知识图谱问答
- 基于显示特征的知识检索
- 关键词检索
- 文本蕴含推理
- 逻辑表达式
给出了许多研究进展。
- 基于端到端的知识图谱问答
- LSTM
- Attention Model
- Memory Network
其中有部分问题: 1. 如何学习? - RNN - CNN - Transformer 2. 问句如何表示? - 取所有词向量的平均值 - 关注答案不同的部分,问句的表示应该问句的不同部分 - 等 3. 考虑多维度的相似度 - 从多个角度计算问句和知识的语义匹配(语义相似度) - 问句如何表示? - 依据问答特点,考虑答案不同维度的信息
PPT 中给出了许多研究进展,包括最基本的做法。

基于神经符号计算的知识图谱问答
 - 基于序列学习的解析方法 + seq2seq * RNN-based * with Attention + 基于序列学习的神经符号计算
- 基于序列学习的解析方法 + seq2seq * RNN-based * with Attention + 基于序列学习的神经符号计算
就是运用基于符号语义解析的知识图谱问答的原理,让神经网络生成这些符号,而不是生成文字。
* Seq2Tree- 基于动作序列的解析方法
- Seq2Action
- 基于对战神经网络的端到端问答方法
总结
限定域的深度问答的准确度比较高,开放域的深度问答的准确度还是处于较低的水平。 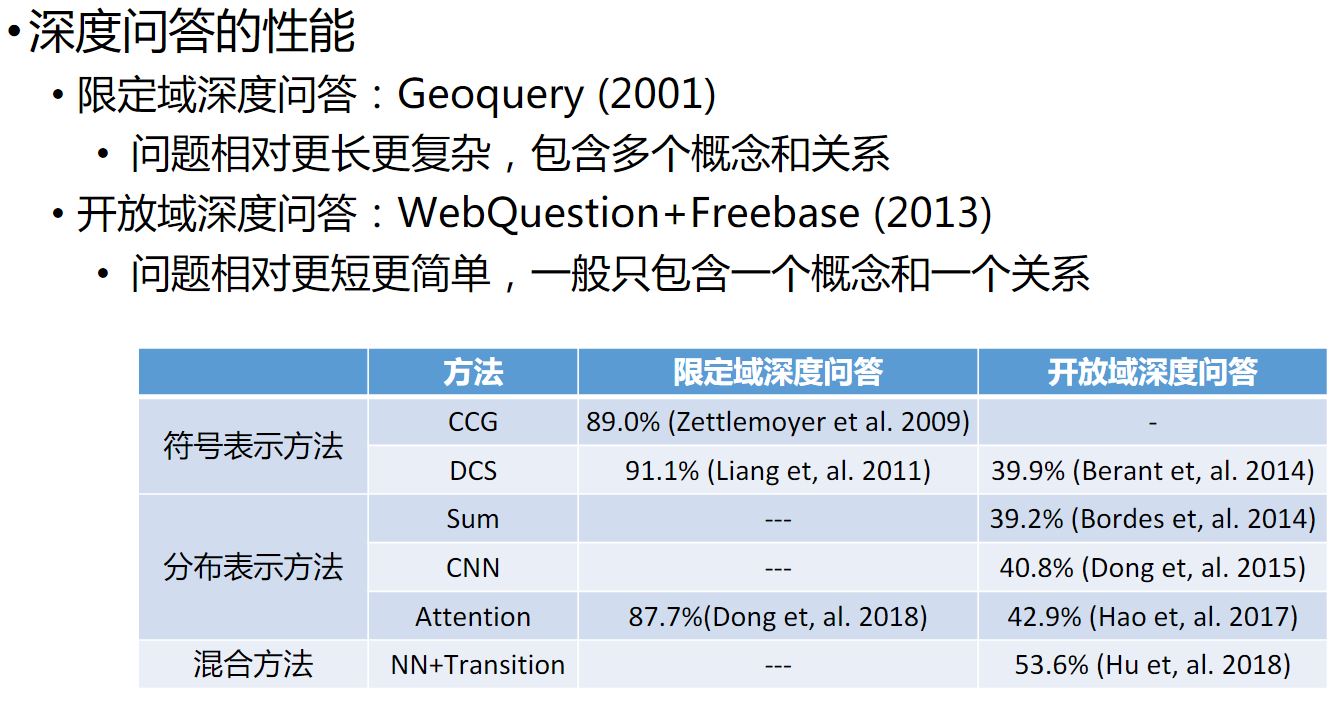
对话系统
对话系统也可以直白的称为聊天机器人。 目前 54% 的用户会使用闲聊(开放域对话)功能。26% 的用户会选择使用某些功能性功能,比如查出行路线、查天气等。其余小部分用户使用其他的功能。 目前大部分的聊天机器人都基于微软小冰。 
聊天机器人一共分为两种: 1. 检索式 2. 生成式
Response Selection for Retrieval-based Chatbots
检索式又分为单轮和多轮。 单轮不考虑回复历史。下图展示了一个单轮回复的场景,用户提出一个问题,机器人需要在一堆回复中检索出一个最有可能的结果来对用户进行回复。多轮回复与单轮类似,只不过多轮需要考虑上下文的对话。最后也是选择一个最优可能的结果进行回复。 
对于单轮: 回复不只回复 Top1 的候选回复,而是要训练一个 classifier,从而随机地返回一个回复。因为如果回复总是为同一个,用户可能会感觉很无聊。 对于多轮: 有一些挑战: - A hierarchical data structure + Words -> utterances -> session - Information redundancy + Not all words and utterances are useful for response selection - Logics + Order of utterances matters in response selection + Long-term dependencies among words and utterances + Constraints to proper responses
下面是检索式单轮回复系统架构图和多轮回复系统架构图的对比。 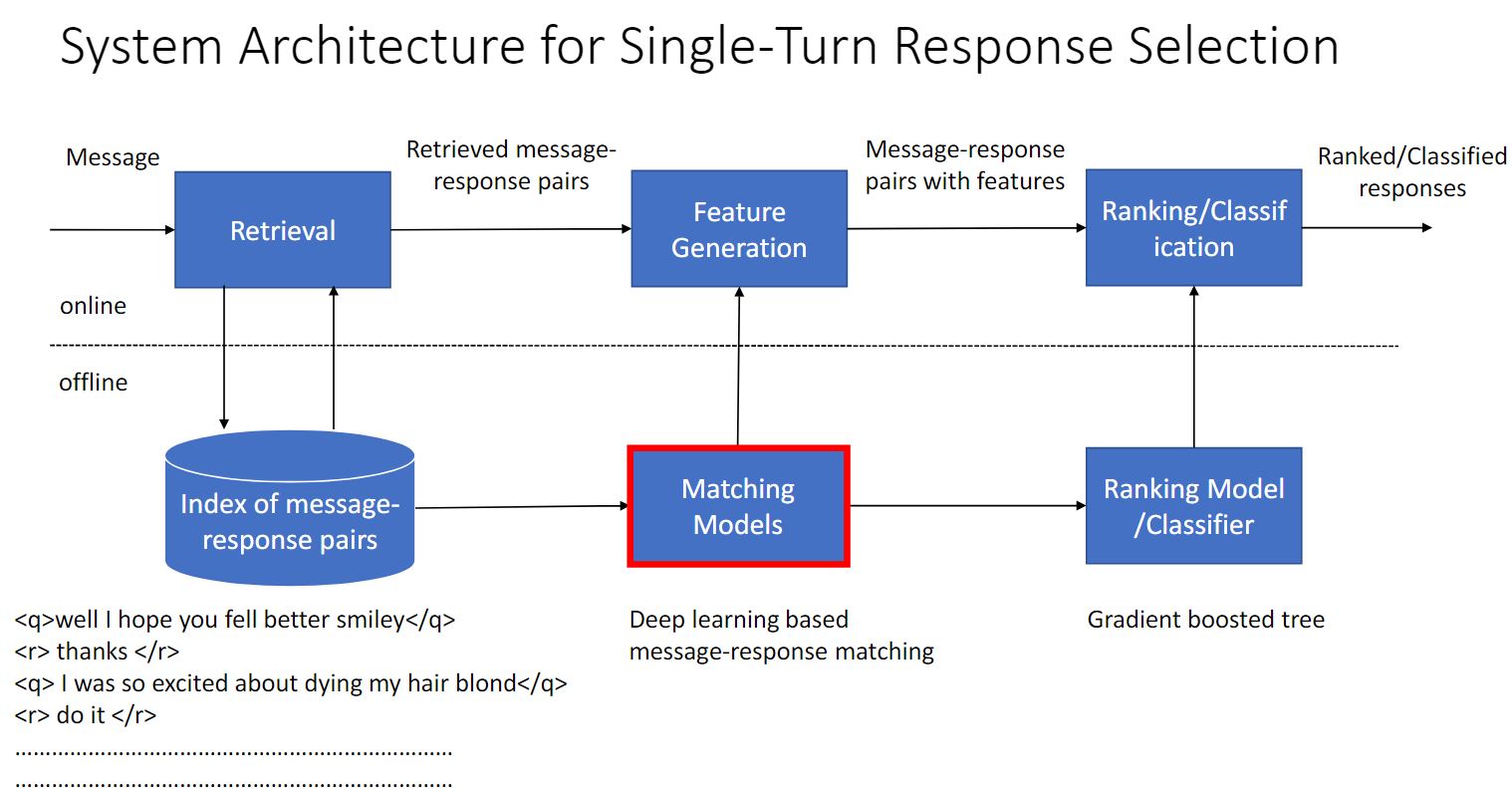
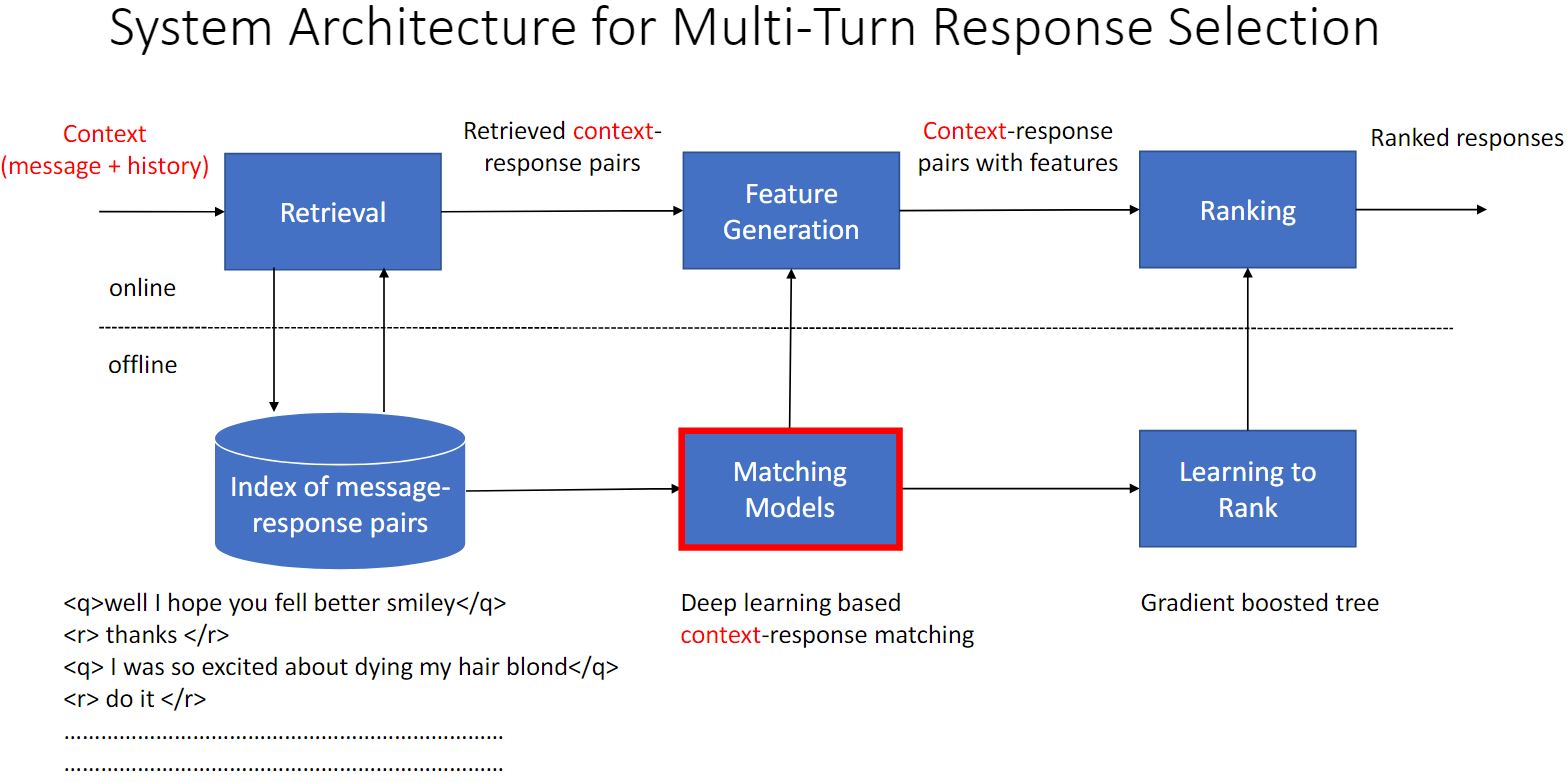
单轮回复中使用的模型
一共有两种框架,分别为:Framework I 和 Framework II。 Framework I 和 Framework II 的区别是: 1. Framework I 是将句子表示为向量,Framework II 将字表示为向量。
Framework I 和 Framework II 的比较: - Efficacy(功效): 1. 一般来讲,在外界公布出的数据集上,Framework II 模型比 Framework I 模型更好。因为在 Framework II 中的 interaction 充分保留了一个 message-response pair 中的匹配信息。 - Efficiency(效率): 1. 由于过多的 interaction,Framework II 的模型普遍比 Framework I 的模型在计算上代价更大。 2. 由于可以预先计算 messages and responses 的表示并将它们以索引形式存储。所以当对线上响应时间有严格要求时, Framework I 的模型更可取。
下图是 Framework I 的架构,其中最下层的 sentence embedding layer 大概就是词向量,然后需要经过一个 Representation function(这个 function 下面会给出架构)。最后将已经经过 Representation function 转换后的 q 和 r 送入 Matching layer,该层有一个 Matching function(这个 function 下面也会给出架构)。 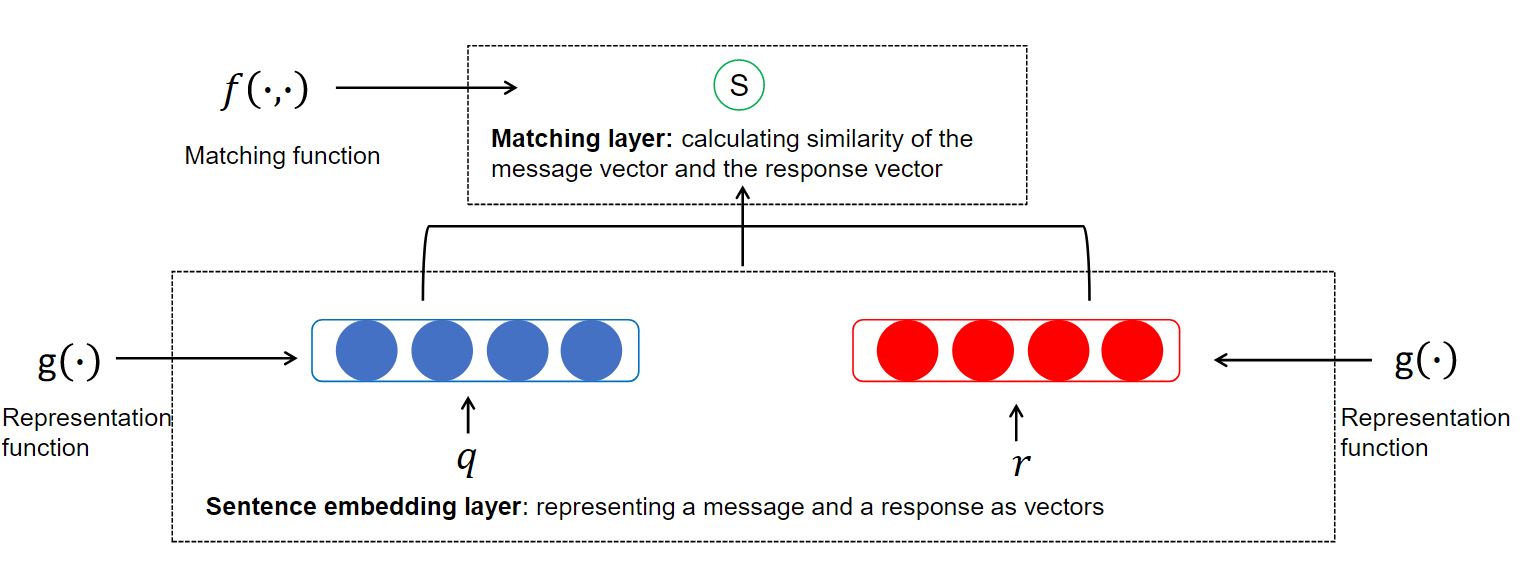
下图是 Representation funtion 的结构: 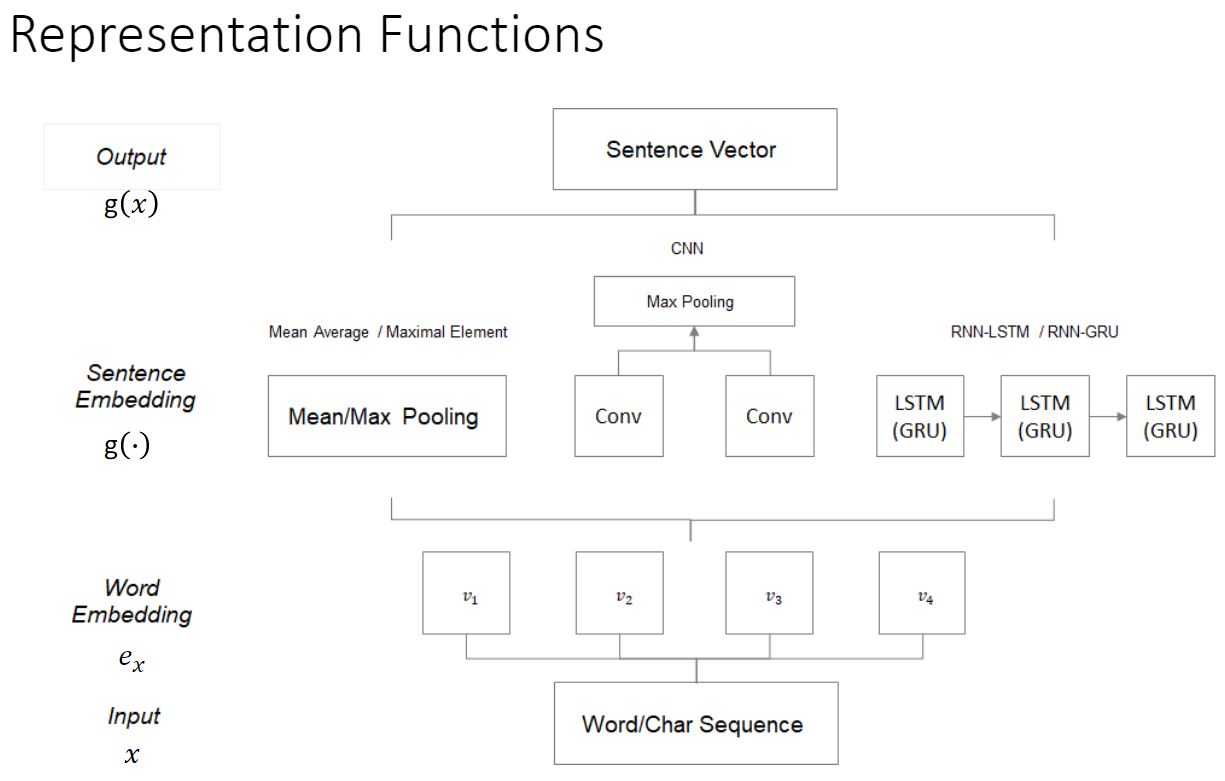
下图是 Matching funtion 的结构: 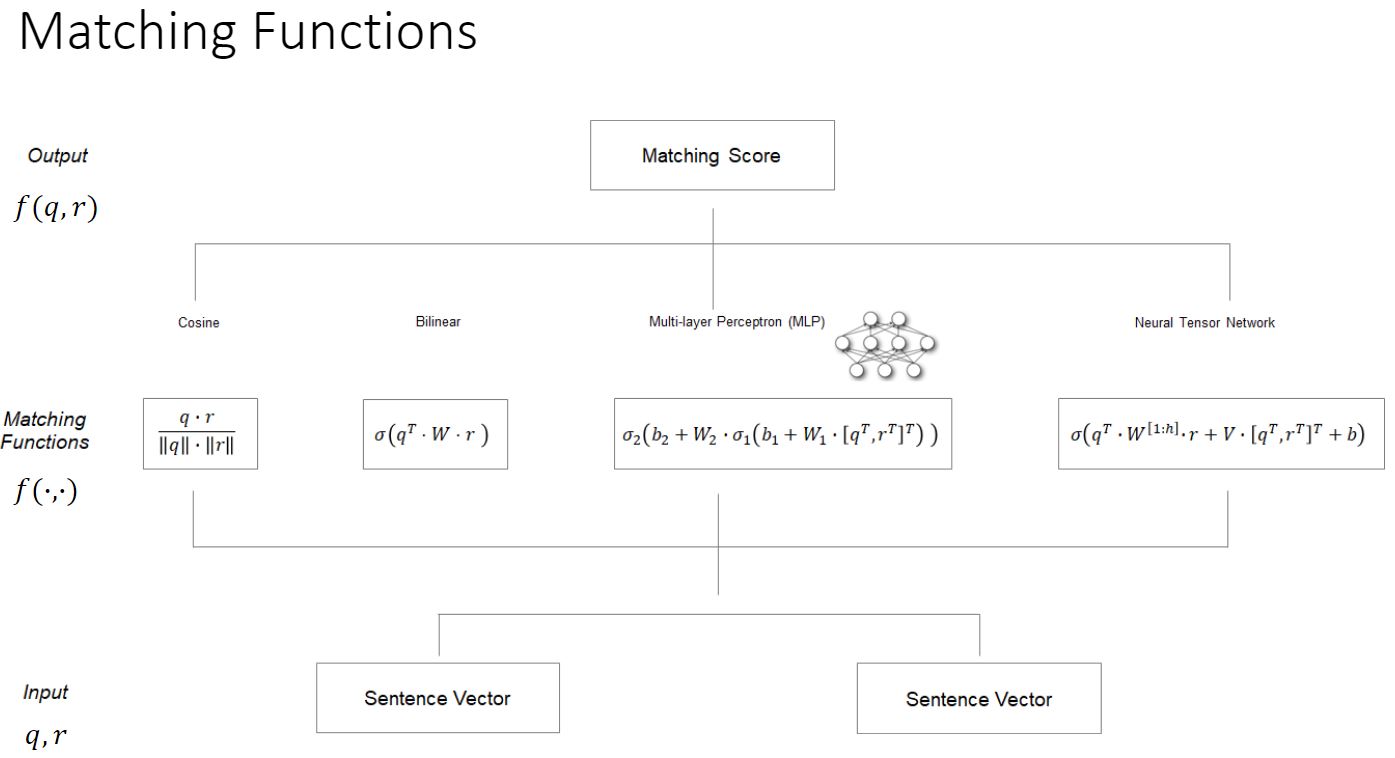
有一些特殊的模型:Arc-I,Attentive LSTM 等
Framework II 的架构与 Framework I 类似,只是多了一个 Interaction Function。 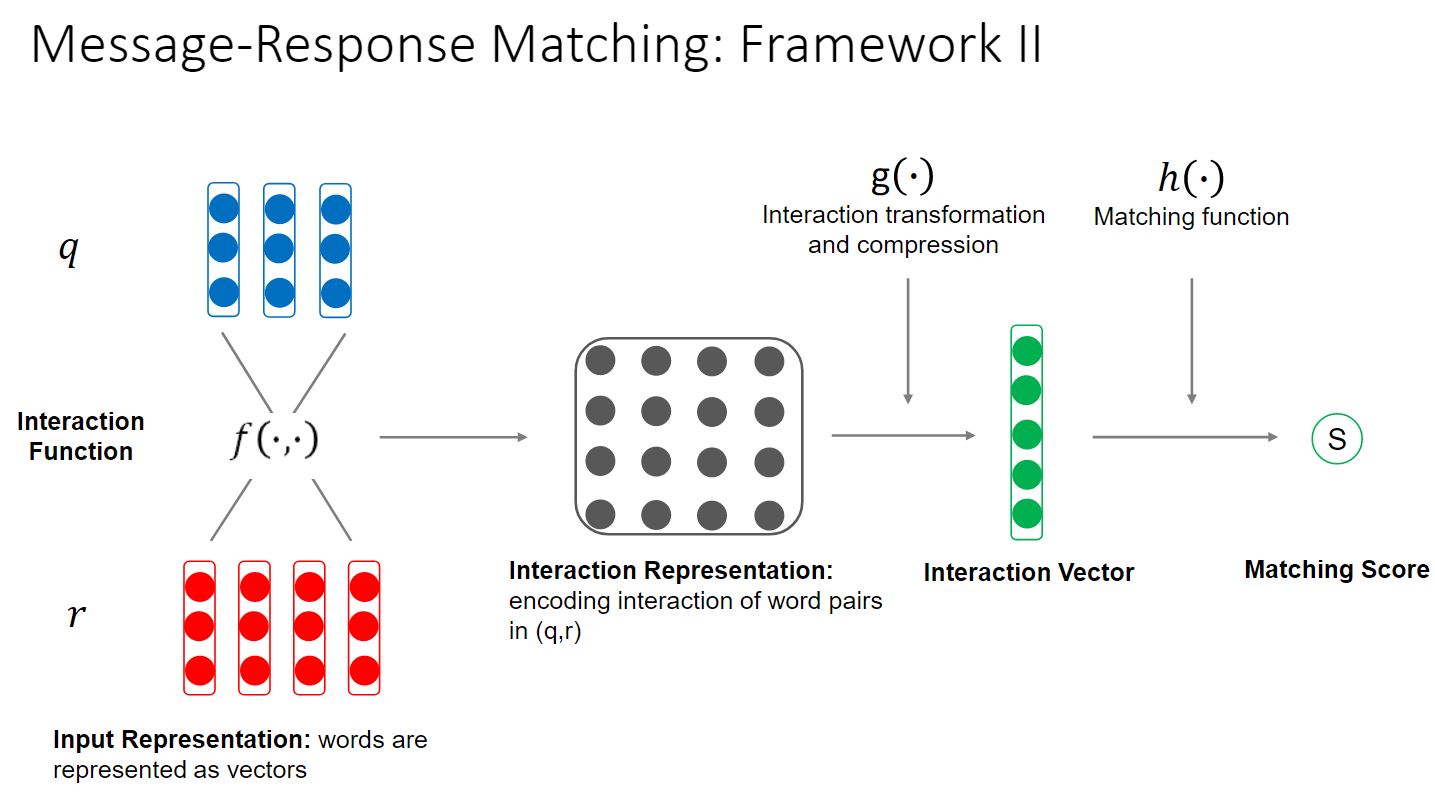
Interaction 由两种形式: 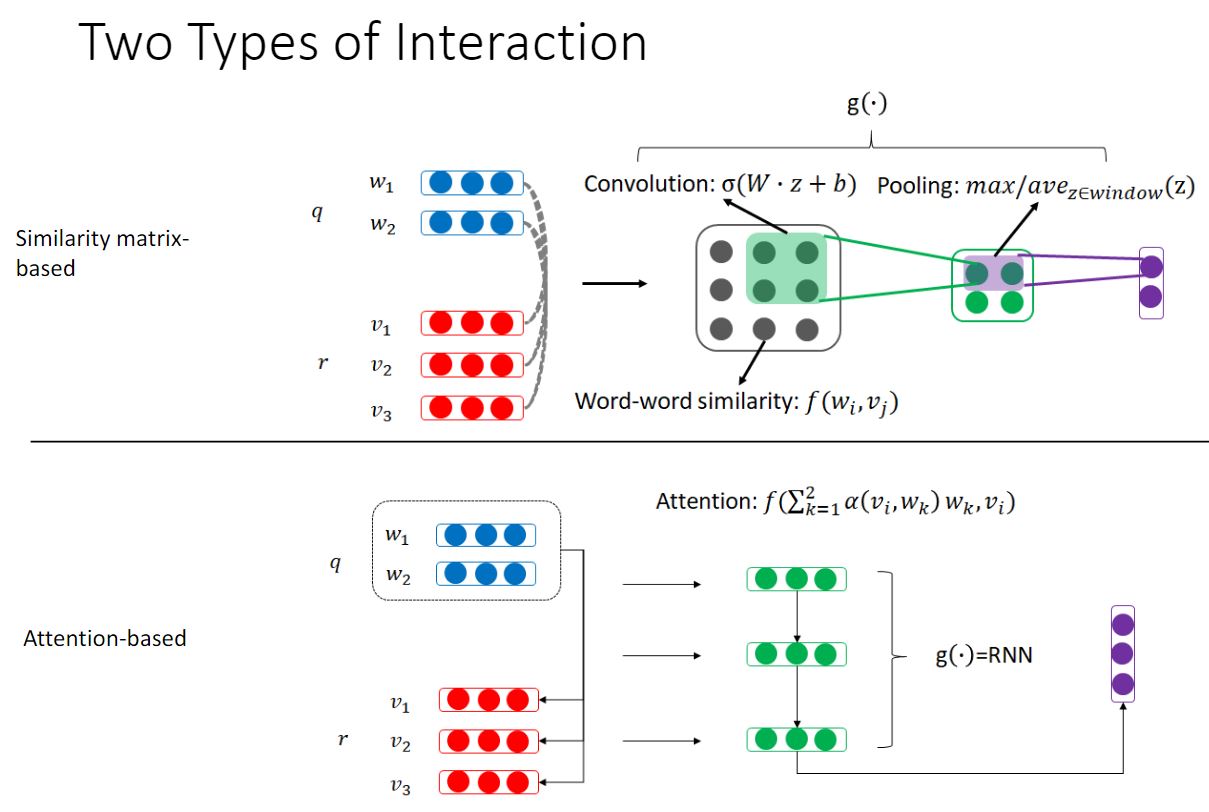
有一些特殊的模型:Match Pyramid,Match LSTM 等
PPT 中有数据集。以及很多 reference。
多轮回复中使用的模型
对于多轮回复也有两种框架,分别为:Framework I 和 Framework II。 具体的架构略。PPT 里都有。
