本文虽然理了一遍神经网络的知识点,但还是有些地方不明白,文中对此进行了提问。
大纲
| 序号 | 描述的内容 |
|---|---|
| 2~4 | 神经网络和深度学习的发展史。 |
| 5 | 从二元分类开始。 |
| 6~10 | 浅层神经网络的介绍。如神经网络中一些参数代表的意思、激活函数、梯度下降、随机初始化。 |
| 11~15 | 深层神经网络的介绍。正向传播和反向传播中向量化后的计算、参数和超参数、神经网络和大脑的关系。 |
| 16 | 一个Simple NN的例子。 |
| 17~22 | 深度学习的实用性层面。数据切分、偏差与方差、正则化、dropout、其他正则化方法、均值归一化、梯度消失和梯度爆炸、梯度检验。 |
| 23~25 | 一些优化算法。Mini-batch、指数加权平均、Momentum、RMSprop、Adam、Adagrad。 |
| 26~29 | 超参数调试、Batch正则化、激活函数以及一些深度学习框架。 |
| 30~end | 本文略长,后序的文章请看对应章节的链接。 |
神经网络和深度学习的发展
TODO
神经网络和深度学习的关系
TODO
为什么要深度学习
TODO
从二元分类开始
暂时省略,因为这里已经会了。
神经网络的表示
规定如下,l:第几层;w:权重值;b:偏差;z:输出值;a:激活值;i,j:都代表第几个神经元,如\(w^l_i\)代表第l层的第i个权重值;W:向量化后的权重值;Z:向量化后的输出值;A:向量化后的激活值;\(\alpha\):学习速率;\(\lambda\):正则化项;
如果输出值z和激活值a无法理解或者区分,没关系,继续往下看就知道了。 如下图所示,一般规定input layer为第0层,不算入神经网络的层数中,所以下图是一个三层神经网络架构。 1. input layer的输入值被称为x,下图一共有三个输入所以分别被称为\(x_1\ x_2\ x_3\)。为了方便起见,可以将input layer的值x以\(a^0\)来代替,下面解释a代表什么。 2. hidden layer中的值被称为a——激活值(activations),图中有四个神经元,所以分别被称为\(a^1_1\ a^1_2\ a^1_3\),上标代表着所在神经网络中的第几层,下标代表着所在层中的第几个神经元。如果表示成向量形式就是 \[ \begin{pmatrix} x_1\\ x_2\\ x_3\\ \end{pmatrix} = \begin{pmatrix} a^0_1\\ a^0_2\\ a^0_3\\ \end{pmatrix} 和 \begin{pmatrix} a^1_1\\ a^1_2\\ a^1_3\\ a^1_4\\ \end{pmatrix} 和 \begin{pmatrix} a^2_1\\ a^2_2\\ a^2_3\\ a^2_4\\ \end{pmatrix} 和 \begin{pmatrix} a^3_1\\ \end{pmatrix} \]
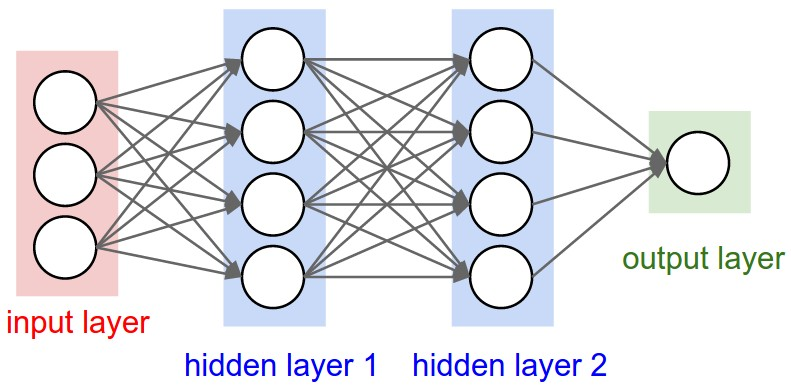
神经网络中神经元的一些参数的含义,特别解释w的含义
hidden layer和output layer的每个神经元都有几个参数。分别为\(w^l\ b^l\),对照上图,这里的\(w^l\)是一个(4,3)的矩阵,\(b^l\)是一个(4,1)的向量。解释如下: \[
\begin{cases}
z^1_1 = a^0_1 * w^1_{11} + a^0_2 * w^1_{12} + a^0_3 * w^1_{13} + b^1_1\\
z^1_2 = a^0_1 * w^1_{21} + a^0_2 * w^1_{22} + a^0_3 * w^1_{23} + b^1_2\\
z^1_3 = a^0_1 * w^1_{31} + a^0_2 * w^1_{32} + a^0_3 * w^1_{33} + b^1_3\\
z^1_4 = a^0_1 * w^1_{41} + a^0_2 * w^1_{42} + a^0_3 * w^1_{43} + b^1_4\\
\end{cases}
\] 可以看到一个公式中有三个w和一个b,一共有四个公式。\(w^l_{ij}\)代表第l-1层的第j个神经元到第l层的第i个神经元上的w。如\(w^1_{12}\)代表第0层的第2个神经元到第1层的第1个神经元上的w。注意这里的i和j实际上是与直觉相反的,也就是说按直觉来看应该是\(w^l_{ji}\)才正常。如果对w的表示有疑惑的,可以看这篇。 注意下这里的z是输出值,之前一直在说hidden layer中的值是a——激活值,其实a就是将z放到一个激活函数(activation function)中得到的一个值,这个激活函数是随用户挑选的,如果不能理解激活函数是什么,就暂时理解为激活函数自己想设成什么就设成什么。 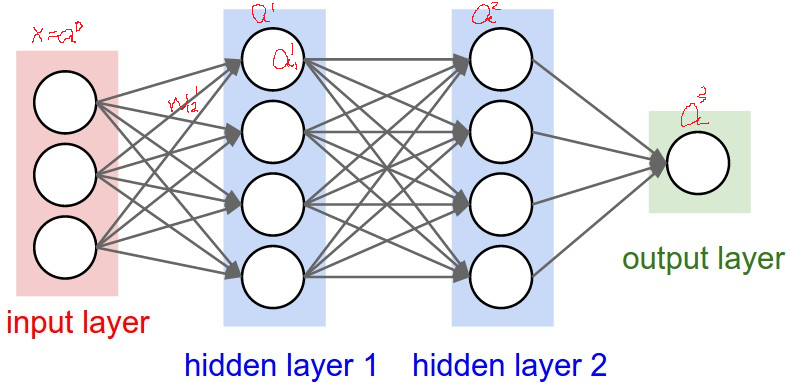
神经网络中的输出是怎么计算的
以一个样本为例
第0层是输入层,所以是不需要计算的,x我本来就有,我还计算什么?对吧。从hidden layer1开始到output layer每一层都需要计算一连串的值,下面给出第一层的计算公式: \[ \begin{cases} z^1_1 = a^0_1 * w^1_{11} + a^0_2 * w^1_{12} + a^0_3 * w^1_{13} + b^1_1,a^1_1 = \sigma(z^1_1)\\ z^1_2 = a^0_1 * w^1_{21} + a^0_2 * w^1_{22} + a^0_3 * w^1_{23} + b^1_2,a^1_2 = \sigma(z^1_2)\\ z^1_3 = a^0_1 * w^1_{31} + a^0_2 * w^1_{32} + a^0_3 * w^1_{33} + b^1_3,a^1_3 = \sigma(z^1_3)\\ z^1_4 = a^0_1 * w^1_{41} + a^0_2 * w^1_{42} + a^0_3 * w^1_{43} + b^1_4,a^1_3 = \sigma(z^1_4)\\ \end{cases} \] 这里的\(\sigma(z)\)函数其实就是上面说的激活函数,一般来讲\(\sigma\)这个符号特指sigmoid function: \(\frac{1}{1+e^{-z}}\)。 这4行公式其实在上面已经给出部分,每一行包含两个公式,也就是说一个神经元中实际上先得到了z,然后再通过激活函数将z转为a。这里可能会有疑惑,已经得到z了为什么还要用一个函数将z转为a呢?这样不是毫无意义?下面有一部分会具体解释,也可以看下面几篇的解释: 神经网络激励函数的作用是什么?有没有形象的解释? 神经网络激活函数的作用是什么? 现在回到本文,正如我上面所说,我一共写了四个公式(激活函数现在暂时不看),所以我要分别计算四个公式,也就是说要计算四次。那么有没有办法只计算一次就得到所有结果呢?答案是向量化(vectorization),现在开始用向量化来解决这个问题。 \[ \begin{pmatrix} z^1_1\\ z^1_2\\ z^1_3\\ z^1_4\\ \end{pmatrix} = \begin{pmatrix} w^1_{11}&w^1_{12}&w^1_{13}\\ w^1_{21}&w^1_{22}&w^1_{23}\\ w^1_{31}&w^1_{32}&w^1_{33}\\ w^1_{41}&w^1_{42}&w^1_{43}\\ \end{pmatrix} * \begin{pmatrix} a^0_1\\ a^0_2\\ a^0_3\\ \end{pmatrix} + \begin{pmatrix} b^1_1\\ b^1_2\\ b^1_3\\ b^1_4\\ \end{pmatrix} \] \(===>\ z^1 = w^1 * a^0 + b^1\) 以下是整个神经网络的计算过程,也就是说只需要下面6行就可以代替上文占据几个屏幕的内容。 \[ \begin{array}{c|} z^1 = w^1 * a^0 + b^1\\ a^1 = \sigma(z^1)\\ z^2 = w^2 * a^1 + b^2\\ a^2 = \sigma(z^2)\\ z^3 = w^3 * a^2 + b^3\\ a^3 = \sigma(z^3)\\ \end{array} =>记为P \] 最后一个a就是整个神经网络的输出值,也就是预测值(prediction),也可以用\(\hat{y}\)表示,自然\(\hat{y} = a^3\)。
向量化计算多个样本
上面我没有特意地说明其实我们只使用了一个样本,我们一直在使用\(a^0_1\ a^0_2\ a^0_3\),但是\(a^0_1\ a^0_2\ a^0_3\)实际上只是一个样本。\(a^0\)代表的是一个样本,\(a^0_1\)代表的是样本中的第一个特征,如果不明白我可以举个例子:\(a^0_1\)代表天气样本中的第一个特征——温度,\(a^0_2\)代表湿度,\(a^0_3\)代表PM2.5,\(a^0\)代表整一个天气样本。 那么如果有成千上万个样本,总不能使用P计算成千上万次吧。这里再次使用向量化进行计算。 \[ \begin{pmatrix} z^{11}_1&z^{12}_1&\cdots\\ z^{11}_2&z^{12}_2&\cdots\\ z^{11}_3&z^{12}_3&\cdots\\ z^{11}_4&z^{12}_4&\cdots\\ \end{pmatrix} = \begin{pmatrix} w^1_{11}&w^1_{12}&w^1_{13}\\ w^1_{21}&w^1_{22}&w^1_{23}\\ w^1_{31}&w^1_{32}&w^1_{33}\\ w^1_{41}&w^1_{42}&w^1_{43}\\ \end{pmatrix} * \begin{pmatrix} a^{01}_1&a^{01}_1&\cdots\\ a^{01}_2&a^{02}_1&\cdots\\ a^{01}_3&a^{03}_1&\cdots\\ \end{pmatrix} + \begin{pmatrix} b^1_1\\ b^1_2\\ b^1_3\\ b^1_4\\ \end{pmatrix} \] \(===>\ z^1 = w^1 * a^0 + b^1\) \[ \begin{pmatrix} z^{21}_1&z^{22}_1&\cdots\\ z^{21}_2&z^{22}_2&\cdots\\ z^{21}_3&z^{22}_3&\cdots\\ z^{21}_4&z^{22}_4&\cdots\\ \end{pmatrix} = \begin{pmatrix} w^2_{11}&w^2_{12}&w^2_{13}&w^2_{14}\\ w^2_{21}&w^2_{22}&w^2_{23}&w^2_{24}\\ w^2_{31}&w^2_{32}&w^2_{33}&w^2_{34}\\ w^2_{41}&w^2_{42}&w^2_{43}&w^2_{44}\\ \end{pmatrix} * \begin{pmatrix} a^{11}_1&a^{11}_1&\cdots\\ a^{11}_2&a^{12}_1&\cdots\\ a^{11}_3&a^{13}_1&\cdots\\ a^{11}_3&a^{14}_1&\cdots\\ \end{pmatrix} + \begin{pmatrix} b^2_1\\ b^2_2\\ b^2_3\\ b^2_4\\ \end{pmatrix} \] \(===>\ z^2 = w^2 * a^1 + b^2\) 省略号代表后面有无数个样本,同理矩阵相乘也可以只用一个字母表示。上标的第二个数字代表是第几个样本,第一个数字依旧是代表所属第几层。
※ 激活函数
| 激活函数名称 | 如何选择 |
|---|---|
| sigmoid | 输出层为二元分类时选用。对于隐藏层来说,基本不会用 sigmoid 函数,因为现在已经有更好的激活函数 缺点:1)会产生梯度消失/弥散(注:sigmoid 不会导致梯度爆炸),详见下面的 Sigmoid 章节;2)不是原点对称;3)计算 exp 较耗时。 |
| tanh | 优点:1)原点对称;2)比 sigmoid 快。 缺点:1)还是有梯度消失 |
| ReLU | 首选 ReLU,如果 ReLU 不行,再换其他形式的 ReLU。观点来源 优点:1)解决了部分梯度消失问题;2)收敛速度更快。 缺点:1)梯度消失的问题没有完全解决,在激活函数(-)部分相当于让神经元死亡,且无法复活。 |
| Leaky ReLU | |
| Parametric ReLU | |
| Randomized ReLU | |
| ELU | |
| SELU | |
| GELU | |
| Swish | |
| softmax | 输出层为多元分类时选用。只适合于输出层 |
| log_softmax |
Sigmoid
上文中我们一直假设使用 sigmoid function 作为激活函数。但是事实上还有很多其他选择,甚至其他的激活函数比sigmoid funtion效果要更好。 上面讲过\(\sigma(z)\)特指 sigmoid function,现在我们将表达式改为:\(a = g(z)\),用g来表示激活函数,它可以是线性的,也可以是非线性的。 引用吴恩达在深度学习视频中的话: > 有一个函数总是比 sigmoid function 表现得更好,就是tanh函数或者叫双曲正切函数,公式为:\(\frac{e^z-e^{-z}}{e^z+e^{-z}}, \, x\in(-1,1)\),在数学上实际是\(\sigma\)函数平移后的版本。 > 事实证明,如果将\(g(z)\)选为 tanh 函数,效果几乎总比 \(\sigma(z)\) 函数要好。
有一个例外是 output layer,它还是使用 sigmoid funtion,因为 output layer 跟普通的分类问题没什么区别,它要得到0~1之间的一个概率。 sigmoid function 的值总是位于 0~1 之间,tanh function 的值总是位于 -1~1 之间。
在 CNN 中 ReLu 激活函数可能是首选,但是对于 RNN 来说,首选是 tanh,而不是 relu。
缺陷
Sigmoid 函数将导致梯度消失。梯度的问题,在下面的章节(21 章左右)中会有讲到,但是此部分只讲 sigmoid 函数的梯度消失问题。 首先我们脑中大概有个 sigmoid 函数的图像,这应该很简单。注意函数的两边,我们发现函数曲线在 \(-\infty\) 方向越来越接近 0,在 \(\infty\) 方向越来越接近 1。以正方向为例,我们可以得知输入 sigmoid 的值越大,sigmoid 的输出值越接近 1。 做一个小小的测试,当输入值为 3 时,输出值为 0.9526,当输入值为 9 时,输出值为 0.9999。可以观察发现,输入值相差巨大的情况下,输出值居然相差无几。当然如果举一个更极端的例子,比如输入 20 和 2000,就会发现输出值都非常接近 1,详见下图。也就是说,输入值相差巨大,但是经过 sigmoid 之后,输出值居然相差无几。换句话说就是一个值在经过 sigmoid 之后被衰减了。通俗来讲,我管你是 2000 还是 20000000,只要经过我 sigmoid,你输出就只能是一个接近 1 的数。这样就是被衰减了。 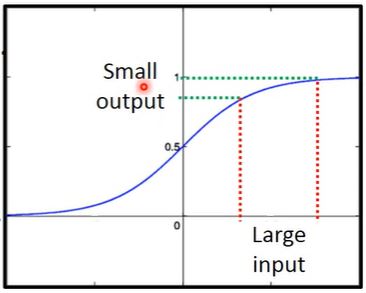
其次我们又知道对于一个神经网络而言,它一般会叠的很深,四五层都很常见。有了以上两个基础,下面举个具体的例子。 我们知道梯度下降算法的公式是 \(W = W - \alpha \Delta W\),在进行一次梯度下降后,对于 W 来说,变化就是 \(\alpha \Delta W\),不严格的说其实只有 \(\Delta W\)。然后将新的 W 传入 sigmoid 函数,我们就会发现 \(\Delta W\) 被衰减了(为什么会衰减上面已经说过了)。而 \(\Delta W\) 其实是梯度,也就是说梯度被衰减了,然后再经过多层神经网络之后,梯度被一减再减。 综上所述,梯度在第一层可能很大,在经过几层 sigmoid 函数之后,可能就减没了。 不过,由于 sigmoid 导数的取值范围是 (0, 0.25),所以梯度也不会很大,但是这仍然架不住多层的神经网络。
ReLU
但是不管是\(\sigma\)或者tanh函数都一个缺点,那就是当z非常大或者非常小时,函数的斜率(导数的梯度)很小。这样会拖慢梯度下降。在机器学习中还有一个函数,即ReLU函数——Rectified Linear Unit,表达式为\(max(0, z)\)。 所以在选择激活函数时有一些经验法则: 1. 如果你的输出值是0或1,那么\(\sigma\)函数很适合做output layer的激活函数,非二元分类的情况下使用tanh函数几乎都比\(\sigma\)优越。藏层单元全用ReLU函数,现在ReLU函数已经是隐藏层的默认激活函数了,大多数人都这么做。 2. 还有个叫Leaky ReLU的函数比ReLU稍微好点,但是目前暂时不是很多人用。
Softmax回归
Sogmoid函数\(\sigma = \frac{1}{1 + e^{-z}}\)适用于二元分类,那么碰到多元分类怎么么办呢?Softmax函数就可以解决这个问题。 Softmax函数计算步骤如下,假设是n元分类: \[
Z^L = W^L * A^{L-1} + b^L\\
t = e^{Z^L}\\
A^L = \frac{e^{Z^L}}{\sum^n_{i=1}t_i},\quad A^L_i = \frac{t_i}{\sum^n_{i=1}t_i}\\
\] 多元分类中每一个神经元代表对应标签的概率是多少,并且将概率相加等于1。 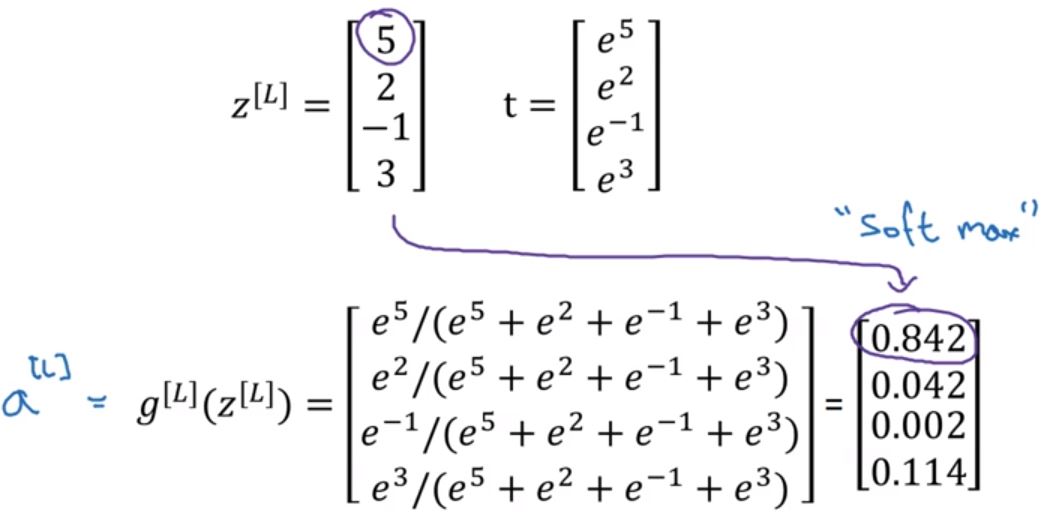
为什么需要非线性激活函数
为什么\(w*x+b=z\)之后,需要使用一个激活函数\(a = \sigma(z)\)?不能不加这个激活函数吗?权重值乘上输入值加上偏差之后直接输出就行了,何必再带入激活函数中?
由于y=bx+c是线性函数,只不过将输入值乘了一个常量并进行位移而已,所以使用非y=bx+c型的激活函数就算是使用了非线性函数。而在神经元中不加激活函数,实际上就是把激活函数设置成y=x这个函数。 那么现在从头再做一次神经网络计算,与上面的区别是这次不加激活函数。 \[ \left \{ \begin{array}{ll} a^1 = w^1 * a^0 + b^1 \qquad这是计算第一层的激活值,现在没有使用激活函数。\\ a^2 = w^2 * a^1 + b^2 \qquad这是计算第二次的激活值,也没有使用激活函数。\\ a^2 = w^2 * (w^1 * a^0 + b^1) + b^2 \qquad消掉a^1,两式合并之后\\ a^2 = w^2 * w^1 * a^0 + w^2 * b^1 + b^2 \qquad合并同类项后\\ a^2 = w' * a^0 + b' \qquad由于w和b只是一堆常数,所以将w'代替w^2 * w^1,b'同理 \end{array} \right. \] 通过上面几个式子发现,我们计算了第一层和第二层之后,结果居然还是一个线性的式子,和最初的输入没有什么差别,也就是说你无论叠了几层hidden layer最后输出还是类似\(a^2 = w' * a^0 + b'\)的式子,那么深度学习的意义在哪呢?还不如直接把hidden layer去掉。所以重点就是线性的hidden layer没有任何用处,因为两个线性方程的组合结果还是线性方程。 只有在一个地方可以使用线性方程,那就是回归问题——线性回归。
梯度下降,反向传播算法——backpropagation解析
Q:首先虽然全部的过程已经理清,但是还有几个问题:为什么要对w求导?梯度下降的意义是什么?为什么使用梯度下降就可以解决误差问题? A:(2020.2.21) 1. 梯度下降算法的推导 2. 深度学习500问笔记#词向量乘上权重以及做梯度下降有什么意义
本节的示例均建立在一个样本的情况下,如果是多个样本经过神经网络,可能略微不同。我看了吴恩达老师的深度学习课程,发现多个样本与一个样本的区别,可能只在偏差b那里会有点不同。 下图以一个三层神经网络为例,说明正向与反向传播过程。由于神经元之间的链接太多会导致混乱,所以下图只链接了第一个神经元。  下图略微简化一下反向传播算法中的导数项,并且完成了最后的权重值优化。值得注意的是:如果cost function不同,下面求导结果会略微不同,本文统一使用\(cost = \frac{1}{m} * \sum{(\hat{y} - y)^2}\),但是神经网络一般是使用交叉熵——crossentropy,其公式为:\(cost = -\frac{1}{m} * (y * log(\hat{y}) + (1 - y) * log(1 - \hat{y}))\)。使用前者,\(\frac{\partial{J}}{\partial{z^{(3)}}} = (a^{(3)} - y) * g'(z^{(3)})\);如果使用后者,\(\frac{\partial{J}}{\partial{z^{(3)}}} = a^{(3)} - y\)。可以看到使用两个不同的代价函数,会有不同的结果,这是因为两个函数求导的结果不一样。而两者对表达式\(\frac{\partial{J}}{\partial{z^{(3)}}}\)的结果只差了一个\(g'(z^{(3)})\),这完全是巧合罢了。
下图略微简化一下反向传播算法中的导数项,并且完成了最后的权重值优化。值得注意的是:如果cost function不同,下面求导结果会略微不同,本文统一使用\(cost = \frac{1}{m} * \sum{(\hat{y} - y)^2}\),但是神经网络一般是使用交叉熵——crossentropy,其公式为:\(cost = -\frac{1}{m} * (y * log(\hat{y}) + (1 - y) * log(1 - \hat{y}))\)。使用前者,\(\frac{\partial{J}}{\partial{z^{(3)}}} = (a^{(3)} - y) * g'(z^{(3)})\);如果使用后者,\(\frac{\partial{J}}{\partial{z^{(3)}}} = a^{(3)} - y\)。可以看到使用两个不同的代价函数,会有不同的结果,这是因为两个函数求导的结果不一样。而两者对表达式\(\frac{\partial{J}}{\partial{z^{(3)}}}\)的结果只差了一个\(g'(z^{(3)})\),这完全是巧合罢了。  另外再提醒一下自己,这里全是以一个样本为例。但是仅仅这样权重已经是一个二维矩阵了,要是如果传入多个样本,权重岂不是是一个三维矩阵?然而不管传入几个样本权重实际上对于不同的样本是没有变化的,所以还是二维矩阵。
另外再提醒一下自己,这里全是以一个样本为例。但是仅仅这样权重已经是一个二维矩阵了,要是如果传入多个样本,权重岂不是是一个三维矩阵?然而不管传入几个样本权重实际上对于不同的样本是没有变化的,所以还是二维矩阵。
※ 随机初始化
对于逻辑回归可以将权重(weight)全部初始化为0,但是对于神经网络来说,将个权重初始化为0,再使用梯度下降会完全无效。实际上将偏差b初始化为0是可以的,但是权重不行。 解释起来太麻烦,详情看吴恩达深度学习——01神经网络和深度学习第三周浅层神经网络,3.11随机初始化。吴恩达老师解释地还是很清楚的。 可以像以下这样设置weight:\(w^l = np.random.randn((2, 2)) * 0.01\)//这可以产生参数为(2, 2)的高斯分布随机变量,后面再成一个很小的数,比如0.01。而对于b,之前说了初始化为0也可以。 对于上式的0.01可能会感到很疑惑,为什么要乘这么一个值。因为我们一般将weight初始化为很小的值,如果weight值很大,最终导致z也很大,那么会落在sigmoid function或者tanh function的平缓部分,会使梯度的写了很小,意味着梯度下降算法会非常慢,所以学习得很慢。
初始化补充
经在作业中做的测试得出如下结论:
| Model | Train accuracy | Problem/Comment |
|---|---|---|
| 3-layer NN with zeros initialization | 50% | fails to break symmetry |
| 3-layer NN with large random initialization | 83% | too large weights |
| 3-layer NN with He initialization | 99% | recommended method |
其中"He initialization"最近(论文是2015年的)新搞出来得初始化算法,现在推荐使用此算法进行初始化。
核对矩阵维数
w的维数应该与dw的维数相同。b和db的维数相同
为什么使用深度表示——Why deep representations
引用在2017course深度学习课程上吴恩达老师的话 >深度神经网络能解决很多问题,其实并不需要很大的神经网络,但是得有深度。得有比较多的隐藏层。
为什么深度神经网络会很好用? 1. 深度神经网络到底在计算什么?假设现在在做一个人脸识别系统。那么神经网络的第一层会去找照片里的边缘部分;第二层会去识别人类的特征,比如耳朵,鼻子,嘴巴;第三层会去识别不同的人脸。如下图: 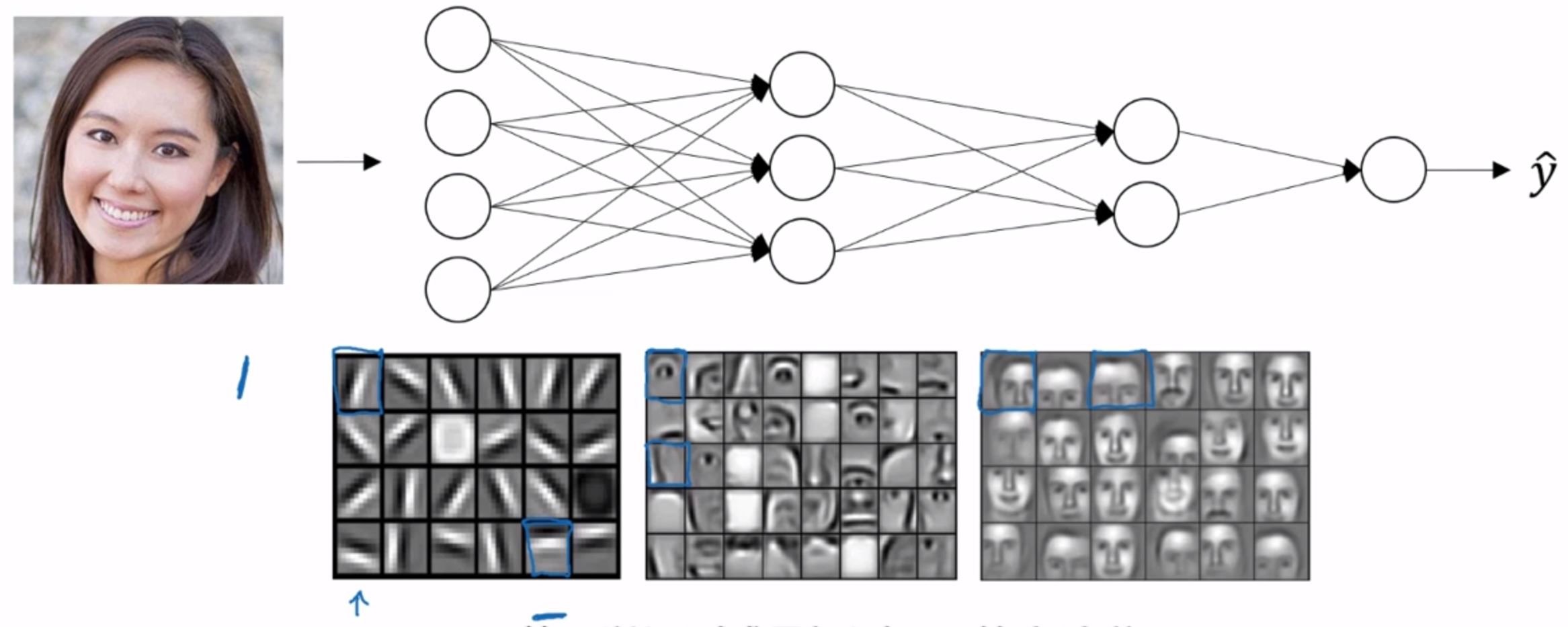 这种识别模式可能难以理解,但是会在卷积神经网络——Convolutional Neural Network中详细解释。 这视频的这一章节有点难以总结,可以看看该视频,总共也就10分钟。
这种识别模式可能难以理解,但是会在卷积神经网络——Convolutional Neural Network中详细解释。 这视频的这一章节有点难以总结,可以看看该视频,总共也就10分钟。
深层神经网络块
此视频中画出了深度神经网络的代码流程。
参数VS超参数
有如下超参数(hyperparameters):W, b, lerning rate \(\alpha\), iterations, hidden layer L, hidden units, choice of activatation function.这些超参数都需要自己设置。 上面这些都是基础的,实际上还有其他的超参数,稍后会涉及到。
神经网络和大脑有什么关系?
计算机视觉、其他深度学习领域或者其他学科在早期可能都受过人类大脑的启发,但是近年来人类将神经网络类比为大脑的次数越来越少,也就是说近年来大家都不怎么认为这二者有关联。
一个Simple NN的例子
本节以下开始利用算法改善深层神经网络 *********************************************************************************************************************************************
训练/开发/测试集
训练集——training set 开发集/交叉验证集/验证集——dev set/cross validation set/validation set 测试集——test set
以前数据量小的时候,比如100个样本、10000个样本。一般将数据按三七分,七份训练集,三份测试集。验证集(以下均称验证集)在训练集中再细分,比如二八分,八份训练集。 但是现在进入大数据时代,验证集和测试集已经没有必要占大量比例了。比如现在有100万的样本,那么验证集和测试集只需要各抽取大约10000的样本即可。也就是98/1/1的比例,甚至验证集和测试集可以再降低占比。
训练集和验证集/测试集分布不匹配
如下图,吴恩达老师建议最好让验证集和测试集匹配,即来自同一源,要都来自网络高清图,要么都来自手机低像素拍摄。  如果直接不设置测试集也是可以的。
如果直接不设置测试集也是可以的。
※ 偏差/方差
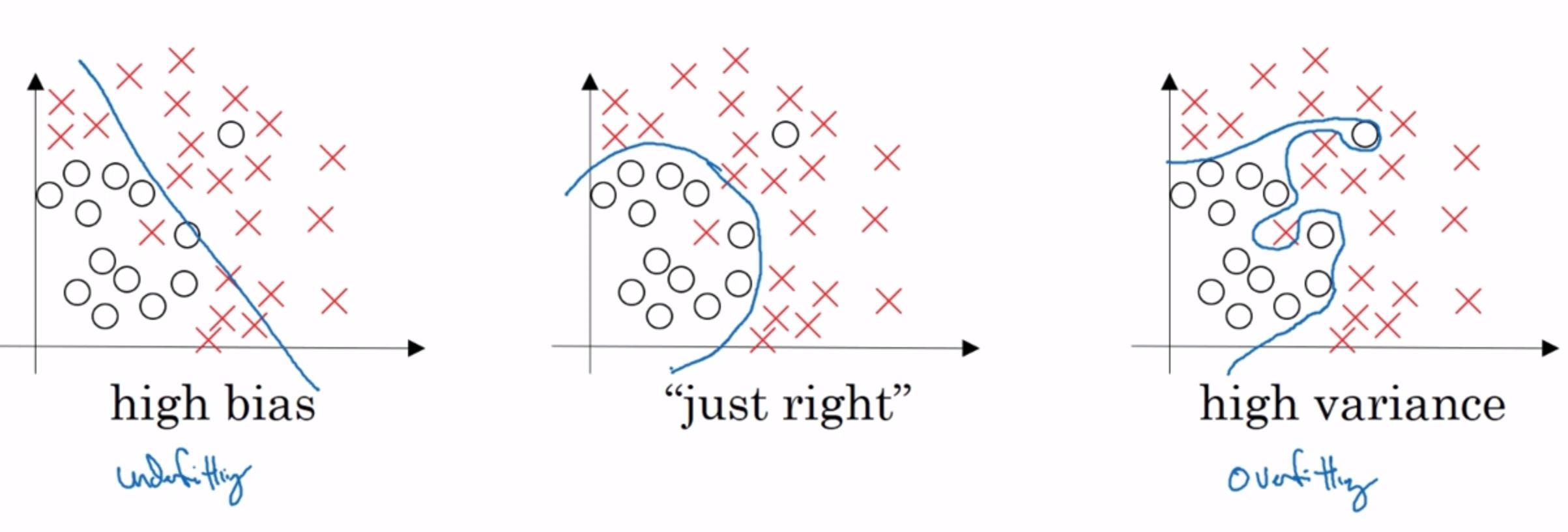
下图讲述了什么是过拟合,什么是欠拟合,如图所示,该神经网络用于判断一张图片是猫还是狗。 左边。训练样本中的误差为1%,这个值已经很小了,但是在验证集上的误差有11%。这就代表了过拟合,试想一下,在训练集上误差很小是因为你的决策界限划分的很好,在上图中的最后一个例子,整条决策界限画的十分完美,但是我们要知道在验证集中,这样一条完美的线肯定不能再拟合的很好。因为训练集和验证集即使来源于同一份数据,他们之间的分布也是不一样的,你训练出一条完美的曲线,在另一份数据集上肯定是过于完美了。所以导致了下图中验证集上的误差有11%。我们称这种情况为高方差——high variance。 中间。训练样本中的误差为15%,这已经不需要再看验证集上的误差了。因为训练集上的误差那么大,肯定是没有拟合好,所以这就是欠拟合,我们称为高偏差——high bais。 右边。如果训练集中的误差很高,验证集上的误差更高,那么可以判断为同时具有高方差和高偏差。 
如果训练集上的误差为0.5%,验证集上的误差为1%。那这就是低方差和低偏差,这是很好结果。 最后一点,以上均建立在人眼判断的误差为0%上以及训练集和验证集来自相同分布。如果人眼判断的误差也高达15%,那么中间的例子也算是可以的结果一般来说最优误差也被称为贝叶斯误差。(不知道语义解析领域如何定义最优误差?) 关于上图同时高方差和高方差,就如同下图紫色线条的决策界限一般。过渡拟合了数据,但是拟合的数据其实狗屁不通。 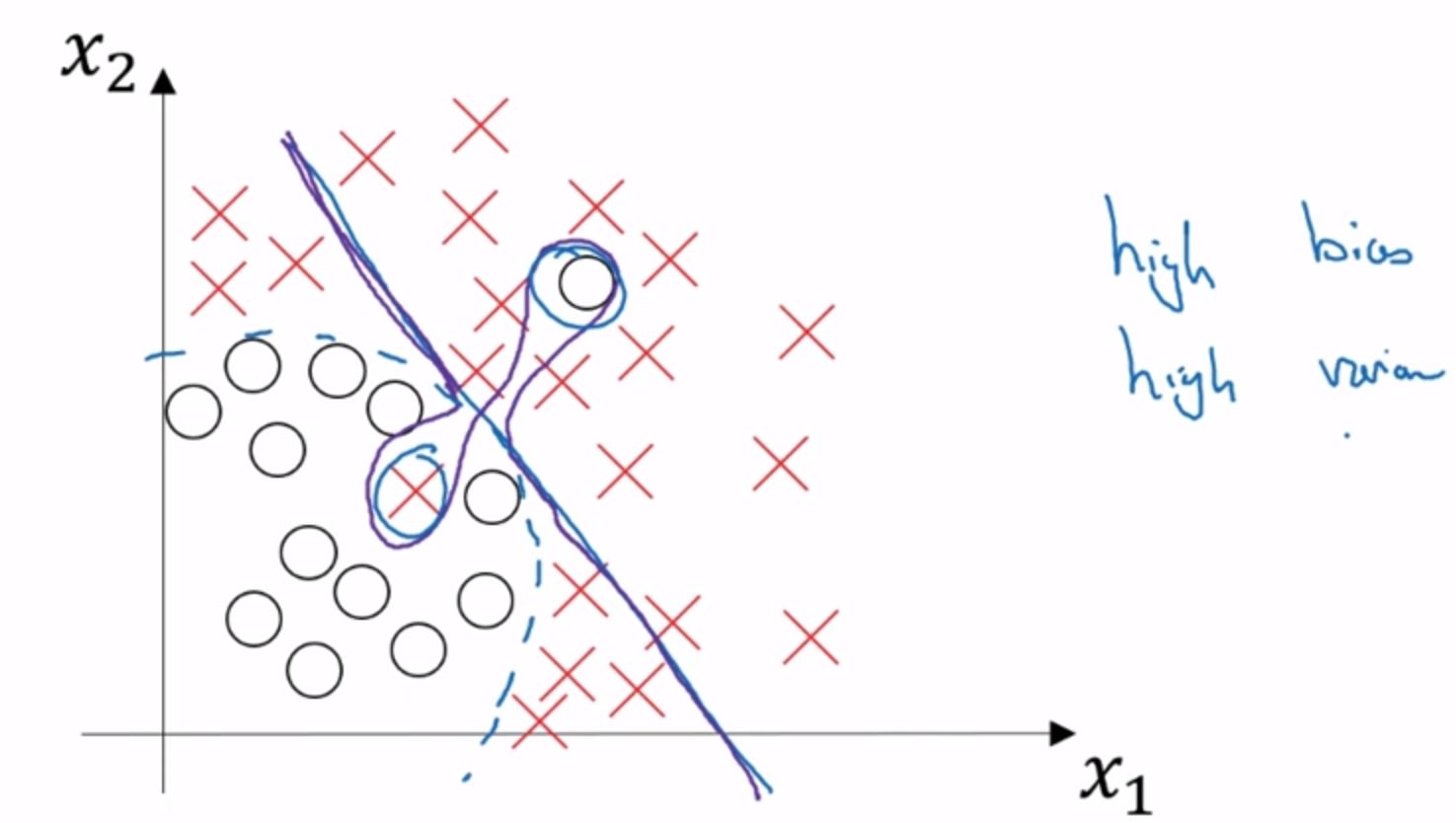
非理想状态下的偏差/方差
那么当上图的理想状态被打破时(比如一张图片很模糊,连人眼也无法分辨),该如何分辨偏差/方差呢? 可以通过对比训练集的 error 和 验证集的 error 来确定是否高方差。比如训练集的 error 为 1%,验证集的为 15%,那就是高方差。实际上跟上面的判断方法一样。
机器学习遇到偏差或方差的解决办法
<p>笔记中都记了,懒得再写一遍了。补充一点,遇到偏差或方差都可以更换神经网络架构,比如换成CNN或者RNN,如果是高偏差还可以使用更大的神经网络。</p>可以看这个6分半中的小视频,机器学习基础。
正则化
如果出现了过拟合,即高方差的情况,第一件想到的事是正则化——regularization。当然也可以增加数据,不过有时候数据不是那么容易获取的。可以对W使用L2范数进行正则化,当然对b也可以进行L2范数正则化,不过一般不加。L2范数的公式为\(||w||^2_2 = \sum_{j=1}^n w^2_j = W^T * W\) 因此代价函数修改为\(cost = \frac{1}{m} \sum^m_{i=1} g(\hat{y}^i, y^i) + \frac{\lambda}{2m}||w||^2_2\),\(\lambda\)是正则化的超参数。这里的w实际上是一个二维矩阵,所以L2范数需要把里面的每一个值的平方都加起来。 如果加入了正则化项,那么在计算dW时有点变化。将会变为:\(dW = dZ * A\_prev + \frac{\lambda}{m} w ^ l\)
为什么正则化可以防止过拟合
dropout
{% note primary %} Q:那么问题又来了,dropout背后的原理是什么? A:[深度学习500问笔记#Dropout-系列问题](https://yan624.github.io/·zcy/AI/深度学习500问笔记.html#Dropout-系列问题)(2020.2.21) {% endnote %}dropout,中文翻译为随机失活。 先将神经网络复制一遍,然后dropout会遍历神经网络的每一层,并设置消除神经网络中结点的概率,比如设置0.5。下图的带X的结点就是准备消除的。另外每一层的概率都可以是不同的,如果在某一层不担心会过拟合可以将概率设为1.0,比如输出层。如果觉得某些层比其他层更容易过拟合,可以把那些层的keep-prob设置的更低。 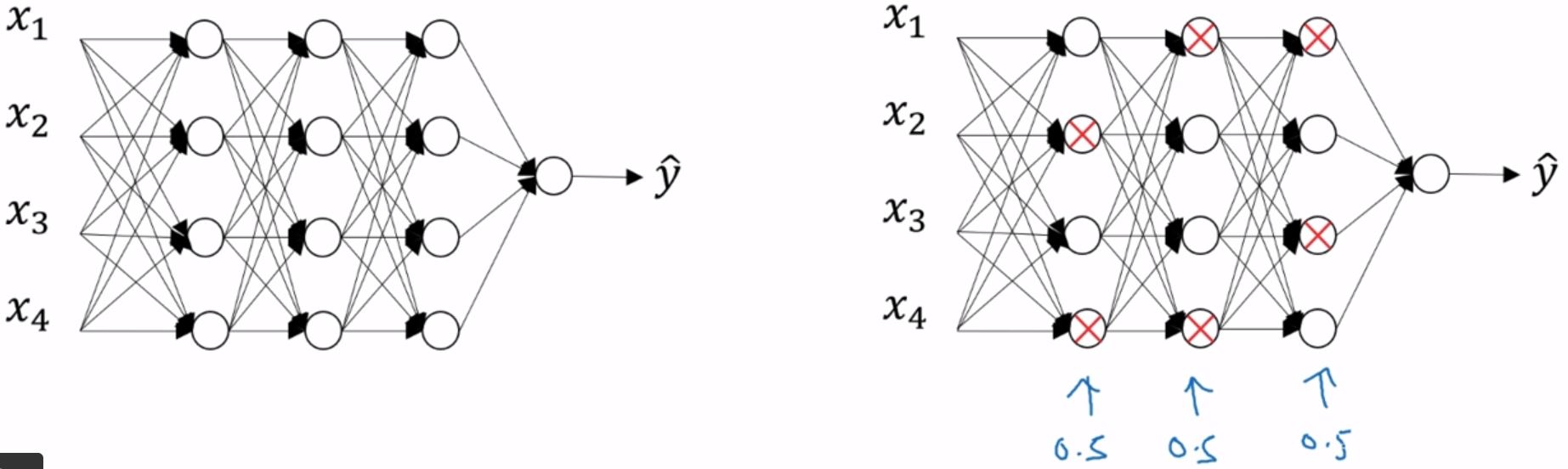 下图则是消除后的神经网络。将结点的进出的链接全部删除。
下图则是消除后的神经网络。将结点的进出的链接全部删除。 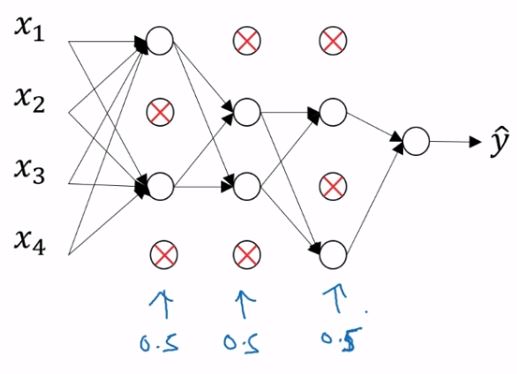 dropout使用之后,就让一个样本进入神经网络进行训练。而对于其他样本也如法炮制,需要再进行复制一遍神经网络,并进行dropout。 以上均是逻辑上的做法,接下来讲实际编码该怎么做。
dropout使用之后,就让一个样本进入神经网络进行训练。而对于其他样本也如法炮制,需要再进行复制一遍神经网络,并进行dropout。 以上均是逻辑上的做法,接下来讲实际编码该怎么做。
- 设置一个结点保留的概率——keep-prob,假设为0.8。\(d^3 = np.random.randn(a^3.shape[0], a^3.shape[1]) < keep-prob\),这样会得到一个True和False的数组,但是python中Ture等于1,False等于0。
- 让\(a^3\)乘上这个向量。\(a^3 = np.multiply(a^3, d^3)\)。由于False等于0,所以变相地将\(a^3\)中的值失活了。
- 最后一步看起来有点奇怪,\(a^3 /= keep-prob\)。 完整代码如下: \[ \begin{cases} d^3 = np.random.randn(a^3.shape[0], a^3.shape[1]) < keep-prob\\ a^3 = np.multiply(a^3, d^3)\\ a^3 /= keep-prob\\ \end{cases} \]
对于最后一步,由于\(Z^4 = W^4 * A^3 + b^4\),由于\(A^3\)被dropout减少0.2,为了使得\(Z^4\)不受影响,所以对\(A^3\)除0.8,来保证\(A^3\)的值不变。由于早期的版本没有除于keep-prob,使得测试阶段,平均值越来越复杂。 最后,从技术上来讲,输入值也可以使用dropout,但是基本不这么做,直接把keep-prob设为1.0即可,当然0.9也可以。不过太低的值一般不会去设置。 以上的步骤被称为Inverted dropout——反向随机失活。 dropout在计算机视觉中用的非常多,甚至成了标配。但要记住一点,dropout是一种正则化方法,为了预防过拟合。所以除非算法过拟合,不然不会使用dropout。由于计算机视觉的特殊性,他们才经常用dropout。 dropout的缺点是使我们失去了代价函数这一调试功能。我们经常使用代价函数得到误差,从而画出曲线图。但是使用dropout之后,这样的曲线图就不再准确了。
测试
在测试阶段不再使用dropout,因为我们不希望输出结果是随机的,如果使用dropout预测会受到干扰。
理解dropout
{% note info %} 略。有点晦涩。 {% endnote %}看视频。。
其他正则化方法
- Data augment——数据增强。如果拟合猫咪图片分类器,可以对原图片做一些处理,来增加数据,比如翻转、旋转、随机裁剪等。
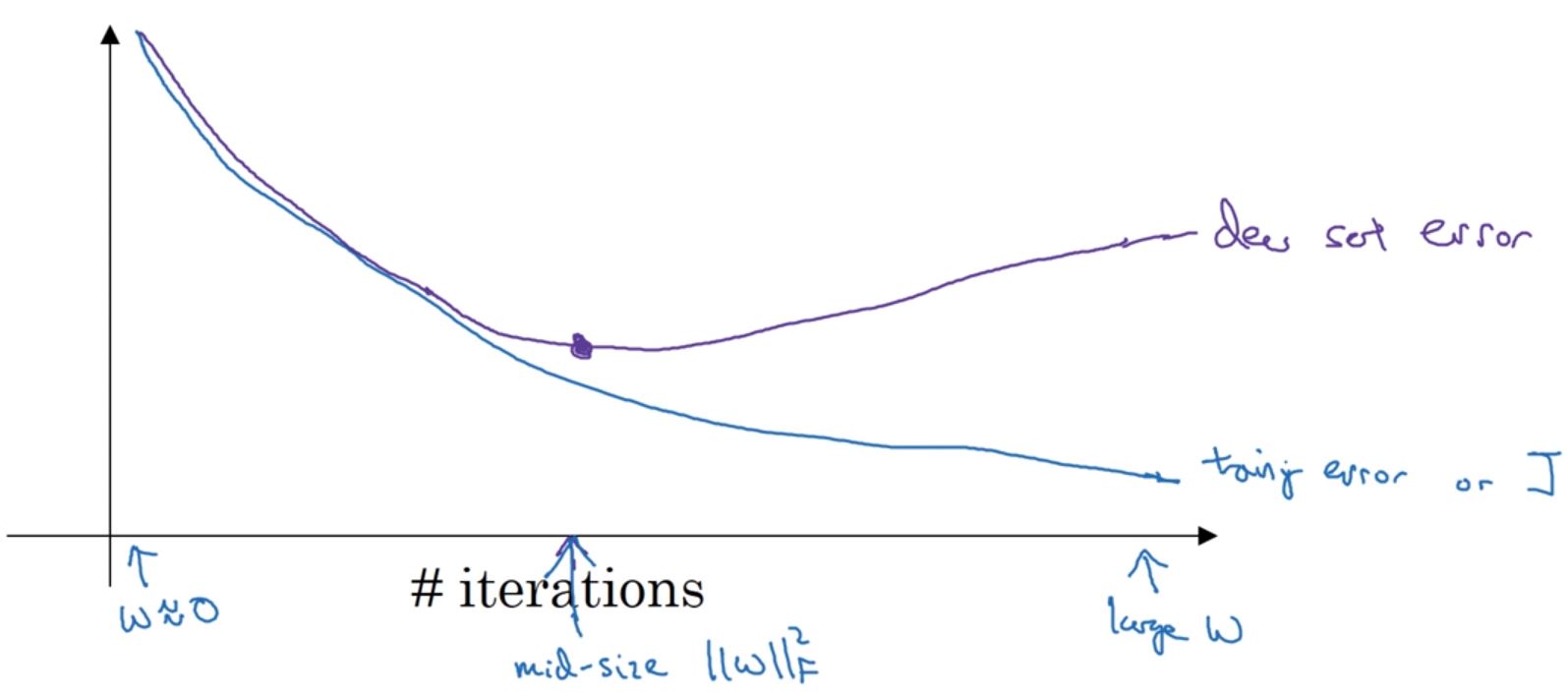
- Early stopping。在训练时画出代价的曲线图,x轴为迭代次数,再绘制验证时的误差。然后选择验证误差曲线图中最低点的迭代次数,下次训练时就改用这个迭代次数,或者也可以在程序中写一个条件判断。如下图:
均值归一化输入
略。其实很简单。梯度消失和梯度爆炸
视频 另外一个参考视频,08:37开始。 另一个13:50~18左右
解决办法
梯度检验
Gradient checking(Grad check). 原理视频 实战视频 梯度检验可以帮助我们发现神经网络中的一些bug。具体原理是,通过数学上导数的定义来确认反向传播算法是否正确。如果学过高数就会知道,使用导数的定义求解和直接使用公式求解,两者结果十分接近或者一模一样。如果二者不一样说明肯定是求错了。 对应于神经网络,那就肯定是代码写错了。具体操作可在视频中看见,每个视频都不超过10分钟。
注意事项
- 不要在训练中使用梯度检验,它只用于调试。
- 如果梯度检验确实发现问题,要检查每一项,看看是哪个i的w和b有问题。
- 记得正则化项,它也被包含在w的梯度中。
- 梯度检验不能和dropout一起用。
在随机初始化时就运行一遍梯度检验;或许在训练一会后可以再运行一遍梯度检验。当W和b接近于0时,梯度下降正确执行在现实中几乎不太可能。吴恩达老师说这条他在现实中几乎不会这么做,并且第五条的翻译,个人感觉翻得有问题,然后看了英文原文后,感觉原文表达得也不是很好,我看不太懂,所以这条就不算进注意事项了。
Mini-batch梯度下降
移至《机器学习中的各种优化算法》。
指数加权平均
移至《机器学习中的各种优化算法》。
※ Learning rate decay
移至《机器学习中的各种优化算法》。
如何为超参数选择范围
上面说了那么多算法,其中包括了许多超参数,那么应该怎么为超参数选择值呢?
超参数的重要程度
按照吴恩达老师的排序,超参数的重要程度如下: 1. learning rate\(\alpha\) 2. Momentum的\(\beta\), hidden layer units, mini-batch size 3. layer的数量,learning rate decay 4. Adam中的\(\beta_1\quad \beta_2\quad \epsilon\)不是很重要,一般按\(0.9\quad 0.99\quad 10^{-8}\)设置
超参数的取值
- 随机取值
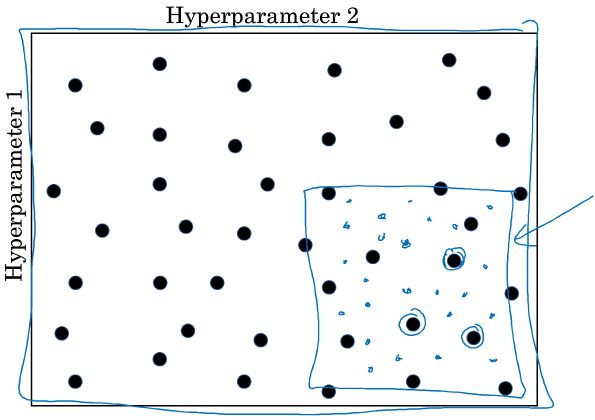
- 从粗糙到精细的策略。首先进行随机取值,发现某个点的效果很好,并且附近的点也很好,然后放大这块区域,进行更密集地取值。下图被圈出来的蓝点就是效果不错的,然后被方框画出一大块区域进行密集地取值或者也可以在这块区域随机取值。
选择合适的范围
补充——用神经网络训练另一个神经网络的超参数
看完李宏毅深度学习后的补充,他在教学视频中也讲述了如何调整超参数,有个说的挺有创意的,就是用神经网络来训练超参数如何取值。典型的例子就是 Swish,它可以用神经网络训练出最好的几个激活函数。
batch normalization——对激活值均值归一化
论文地址 这个原来不是一个算法,它就是让我们对神经网络的每一层都做一次normalization,从而提供性能,而算法是在batch中做的,所以叫这名。 视频地址,第25章写了均值归一化,它对输入值进行了均值归一,更易于算法优化。而batch normalization对激活值进行了均值归一化,说白了是一个东西。
代价函数
代价函数为\(cost(\hat{y}, y) = - \sum^n_{j=1} y_j * log(\hat{y_j})\)。
但是这里可能会有点奇怪。因为二元分类的代价函数是\(cost(\hat{y}, y) = - \sum^n_{j=1} (y_j * log(\hat{y_j}) + (1 - y_j) * log(\hat{1-y_j}))\)。怎么多元分类的表达式那么短?
2020.8.18 更新:不管是二元还是多元,其实公式都是一样的,最后都会缩减到只有一项,因为 y 是一个 one hot 向量。
选择深度学习框架

