论文概要
论文地址,发表于 2017 年。
随着知识库数量的增加,人们越来越希望寻找到一些有效的方法来获取这些资源。现在有几种专门为查询 KBs 设计的语言:SPARQL(rudhommeaux and Seaborne, 2008)。但要使用这些语言,用户不仅需要熟悉它们,还要了解 KBs 的体系结构。相比之下,以自然语言为查询语言的 KB-QA 是一种更友好的方案,近年来已成为研究热点。这项任务以前有两个主流的研究方向: 1. 基于语义解析(semantic parsing-base, SP-based) 2. 基于信息检索(information retrieval-based, IR-based)
现在随着神经网络方法的发展,基于神经网络的 KB-QA 已经取得了令人瞩目的成果。其中至关重要的步骤就是计算问题和候选答案之间的相似性分数,这一步骤的关键一点就是学习它们的表示。然而以往的研究更注重答案的学习表示。例如,Bordes et al. 2014a 考虑候选答案子图的重要性,Dong et al. 2015利用上下文和答案的类型。无论如何,问题的表示终究还是表达不全。现有的方法 Bordes et al., 2014a, b 使用 bag-of-word 模型将问题表示为一个向量,但是这样问题与答案的关联性还是被忽视了。我们认为一个问题应该根据回答时不同的侧重面来表示(注:其实就是想用注意力机制,回答的侧重面可以是答案实体本身、答案类型、答案上下文等)。 因此本文提出了一个端到端的神经网络模型,通过 cross-attention 机制,根据不同的候选答案动态地表示问题及对应的分数。此外还利用了 KB 中的全部知识,旨在将 KB 中丰富的知识集成到答案中,以此缓解 out-of-vocabulary(OOV) 的问题,从而帮助 cross-attention 更精确地表示问题。最后实验结果表明了该方法确实有效。 论文(论文笔记地址)中的方法很有启发性,但是由于简单地选择三个独立的 CNN ,因此过于机械化。所以我们使用了基于 cross-attention 的神经网络模型。 模型架构如下,步骤与之前的论文的步骤类似。1)先找到问题的主题(main entity/topic entity);2)然后在知识库中找到主题相连的结点作为候选答案,3)最后送入 score layer 进行评分,排序分数选出分数最高的候选答案作为正确答案。 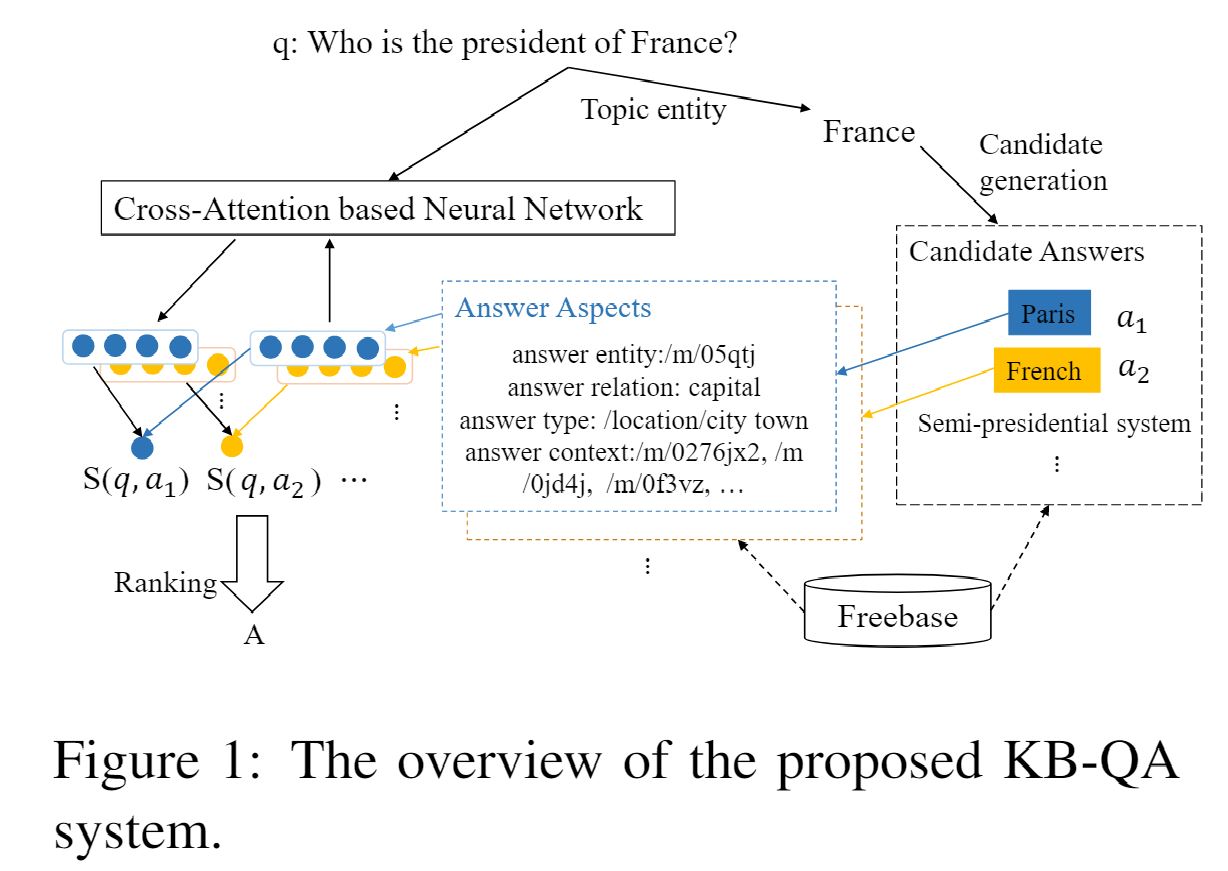
为了方便描述,我们将任何一种基本元素称为资源(resource),无论是实体还是关系。比如 (/m/0f8l9c,location.country.capital,/m/05qtj) 的描述是法国的首都是巴黎,其中的 /m/0f8l9c 和 /m/05qtj 分别代表法国和巴黎,location.country.capital 是一种关系。
我们的方法
候选者生成
略,我已经写过无数遍了。使用 Freebase API 构建的。
The Neural Cross-Attention Model
下图是模型的架构: 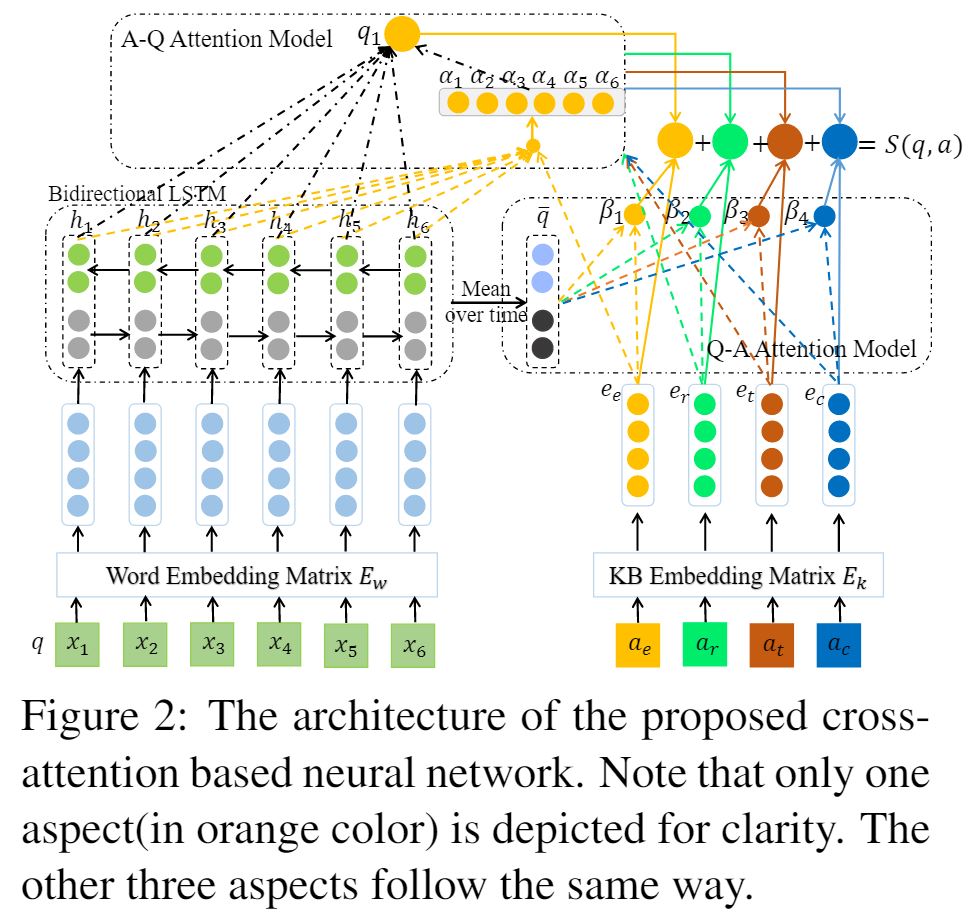
- 问题表示(图 2 中左侧部分显示了处理步骤)
- 使用向量表示问题中的每个单词,这跟其他 NLP 任务差不多,不过它是随机初始化的词嵌入矩阵 \(E_w \in \mathbb{R}^{d \text{x} v_w}\),然后取出对应单词的词向量。d 代表词向量的维度,\(v_w\) 代表词表的大小。
- 将词向量送入 LSTM,值得注意的是我们没有使用单向 LSTM,因为这样一个单词表示只会捕获到之前的单词的信息而不会包含之后的单词。为此我们使用了双向 LSTM 外加 Bahdanau(Bahdanau, 2014) attention 的处理;
- 这样就会获得两个表示 \((\overrightarrow{h_1}, \overrightarrow{h_2}, \dots, \overrightarrow{h_n})\) 以及 \((\overleftarrow{h_1}, \overleftarrow{h_2}, \dots, \overleftarrow{h_n})\),然后将两个表示拼接起来组成 [\(\overrightarrow{h_i};\overleftarrow{h_i}\)],正反向 LSTM 单元的大小都是 \(\frac{d}{2}\)。
- 回答的不同侧面表示(图 2 中右侧下方部分)
- 直接使用 KB 的嵌入矩阵 \(E_k \in \mathbb{R}^{d \text{x} v_k}\),其中 \(v_k\) 代表知识库中资源的大小,该嵌入矩阵随机初始化并在训练时学习表示,使用全局信息对表示的进一步提高将在 3.3 节 Combining Global Knowledge(原论文)描述。具体来说我们使用回答的四个方面:问答实体 \(a_e\),回答关系 \(a_r\),回答类型 \(a_t\),回答上下文 \(a_c\)。它们的嵌入被分别表示为 \(e_e\), \(e_r\), \(e_t\), \(e_c\);
- 值得注意的是问答上下文由多个 KB 资源组成,我们将它们定义为 (\(c_1, c_2, \dots, c_m\)),首先获得它们的嵌入 (\(e_{c_1}, e_{c_2}, \dots, e_{c_m}\)),然后计算它们的平均值 \(e_c = \frac{1}{m} \sum^m_{i=1} e_{c_i}\)
- Cross-Attention model(图 2 中右侧上方部分以及最上方部分),详见 3.2.3 Cross-Attention model
Combining Global Knowledge
Combining Global Knowledg,利用TransE得到knowledge embedding。
模型描述
- 使用了 Bahdanau Attention 处理;
- 使用了双向 LSTM,会得到两个向量,最后将这两个向量拼接在一起,就是 BiLSTM 这层的最终向量。另外正反的 LSTM 的长度都是 \(\frac{d}{2}\);
- 回答通过问答实体 \(a_e\),回答关系 \(a_r\),回答类型 \(a_t\),回答上下文 \(a_c\) 四个方面来表示,其中 ac 是所有词向量的平均值。
相关工作
- Antoine Bordes 等 2014b;
- Antoine Bordes 等 2014a;
- Yih W 等 2014,实际上是基于语义解析的,但是用了词向量;
- Min-Chul Yang 等 2014,实际上是基于语义解析的但是用了词向量;
- Dong 等 2015,这篇是跟我们的文章最相近的(使用了 CNN 而非 RNN + Attention);
- Kun Xu 等 2016b;Xu K 等 2016a。
