本文来自前几篇博文的总结:
任务型对话系统简述
本节简要地概括任务型对话系统,梳理一遍其应用的各项技术。本文的重点是对话状态追踪算法。
信息技术发展的不断进步使人们能够在任何时间、地点以无线连接的方式几乎瞬时地访问信息、应用程序和服务。如今,诸如智能手机和平板电脑已经被广泛地用于访问网络。然而,内容的获取通常仅限于通过浏览器,其依靠传统的图形化界面(graphical user interfaces,GUIs)(López-Cózar et al. 2014)。更先进的人机交互方式亟需被提出,比如拥有更智能、直观和轻便的界面,能够以人类语言交流,提供透明且类人的环境。在影视作品中,通常呈现为智能机器人的形式。然而,目前的技术难以实现这种真正意义上的人类智能。因此,退而求其次,能够以自然语言与人类交流的对话系统受到青睐。
根据其所使用的技术,大致可以被分为基于规则的对话系统(第一代)、基于部分可见马尔可夫决策过程的统计对话系统(第二代)以及基于深度学习的对话系统(第三代)(Dai et al. 2020)。基于深度学习的对话系统与统计对话系统大致相同,只不过其中的各个模块被替换成神经网络模型。本文主要关注基于深度学习的对话系统。此外,由于系统涉及语音交互,在以前也被称为口语对话系统(spoken dialogue system,SDS)。
对话系统大致分为问答、闲聊和任务型三类,本文主要关注任务型对话系统(Task-oriented Dialogue System,TODS)。TODS 旨在为用户完成特定领域中的任务,例如酒店预订、天气查询、景点推荐等。TODS 一般有管道式(pipeline)和端到端(end-to-end)两种实现方式,由于端到端方式的不可控性,目前管道式 TODS 是主流的做法。管道式 TODS 分为六大模块:ASR、SLU、DST、DPL、NLG 和 TTS,每个模块前后相连。下图展示了系统的信息流动。通常,DST 和 DPL 也被并称为对话管理(Dialogue Management,DM)模块。
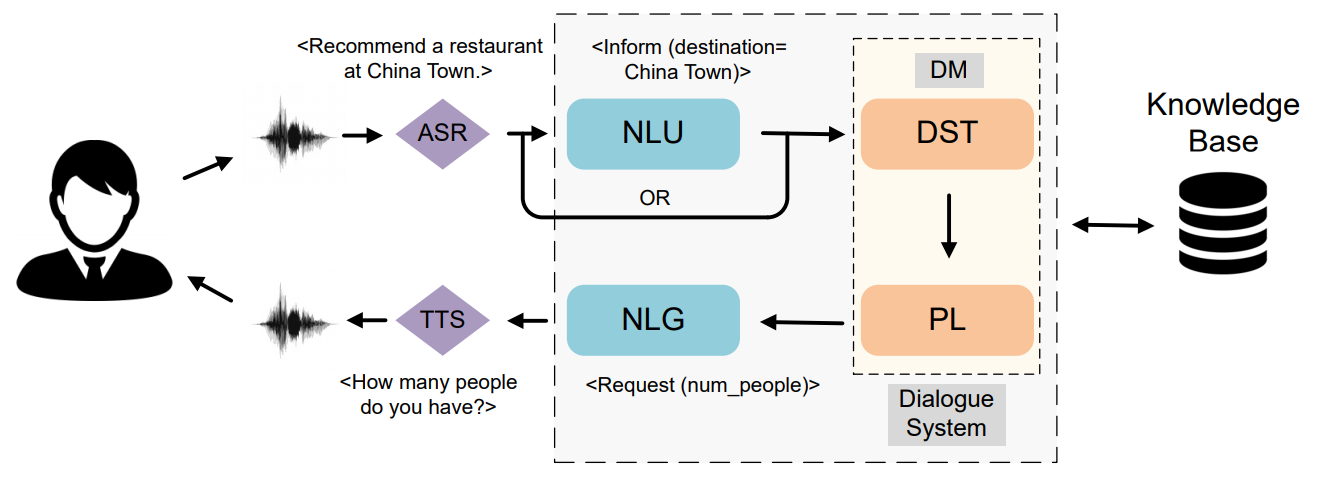
推荐看一些综述了解 TODS 的脉络。
- Review of spoken dialogue systems (López-Cózar et al. 2014):推荐看一下,是 2014 年的论文。它从生活应用角度讲述了 SDS 的必要性,介绍了大量深度学习时代以前的技术。内容包括:
- 各组件的实现技术
- 这些技术的发展并讨论一些现存的应用
- 讨论开发范式,包括脚本语言以及移动应用交互界面的开发
- 描述情感、人格和上下文模型
- 提出一些研究趋势
- A Survey on Dialogue Systems: Recent Advances and New Frontiers:暂时还没细看。
- A Survey on Dialog Management: Recent Advances and Challenges (Dai et al. 2020):主要介绍对话管理,总结了目前所面临的几项痛点。友情提示:知乎上有官方的中文版。
- Recent advances and challenges in task-oriented dialog systems (Z. Zhang et al. 2020)
- Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey (Ni et al. 2021)
引言
对话状态追踪(Dialogue State Tracking,DST)是 TODS 中一个至关重要的模块。它的目标是监控隐藏在对话历史中的用户目标,并将它们表示为由一系列 (domain, slot, value) 三元组组成的对话状态,读作(领域,槽位,槽值)。DST 与语音语言识别(Speech Language Understanding,SLU)紧密相关 (Ni et al. 2021 ch. 3.2) 并且十分相似,个人认为在预测用户目标任务上它们几乎等价。近年,为了避免 SLU 阶段的的误差传播到 DST,通常使用联合模型,即直接将文本或语音输入 DST 并省略 SLU。为此,DST 需要额外承担领域识别和意图识别两项任务。然而,据我所知,为了简便起见,近几年大部分 DST 论文并没有实现这两项任务。
DST 作为任务型对话系统中承上启下的组件,在科研领域中一直都是研究热点。在深度学习时代之前,DST 通常将 SLU 的输出作为输入,即一系列槽值对及其对应的置信度分数,然后使用基于规则或者基于统计的方式更新对话状态 (López-Cózar et al. 2014)。DST 只扮演了更新对话状态的角色。在进入深度学习时代之后,基于数据驱动的神经对话状态追踪开始成为主流,下如无特殊说明,将其简称为 DST。Henderson, Thomson, and Young (2013) 首次在 DST 中探索了深度学习方法 (Ni et al. 2021 ch. 3.2),使模型不再需要复杂的规则。Mrkšić et al. (2017) 借助词向量解决一义多词的现象,摆脱了人工构建语义词典的束缚。虽然以上工作减少了大量的人力成本并且取得了不错的表现,但仍旧:1)泛化能力不强;2)可扩展性不高;3)多领域 DST 是项挑战;4)数据集稀缺。
构建多领域 DST 的主要难点是数据稀缺。Rastogi, Hakkani-Tür, and Heck (2017) 使用三个不同的数据集(DSTC2、Sim-R,Sim-M)首次提出了一个多领域 DST 模型。Ramadan, Budzianowski, and Gašić (2018) 发布了当时最大的多领域数据集 MultiWOZ 1.0 并提出了一个多领域 DST 模型。之后在此基础上又更新了 MultiWOZ 2.0 (Budzianowski et al. 2018)、2.1 (Eric et al. 2019)、2.2 (Zang et al. 2020)、2.3 (Han et al. 2020) 以及 2.4 (Ye, Manotumruksa, and Yilmaz 2021)。基于 MultiWOZ 数据集,涌现了大量的多领域 DST 模型。此外,近年还有研究人员发布了中文任务型对话数据集,比如 CrossWOZ,RiSAWOZ (Quan et al. 2020)。
上文概述了传统 DST 模型以及基于深度学习的基本模型,然后提出了几项缺点并引出了多领域 DST,最后介绍了几种大规模任务型数据集。下文首先对近年(2017—)提出的各种 DST 模型进行归类总结,然后介绍一些 DST 增强技术,最后讨论一下近期的挑战,包括可扩展性、数据稀缺、计算复杂度等。模型的详细对比见下图,“-”代表没有数据,空白代表还没有看过对应内容,其它名词解释为:
- Method: cls=分类模型,gen=生成式模型,span=基于跨度的模型(PtrNet),disc=判别式模型。判别式模型的工作流程是计算槽位表征和槽值表征之间的距离。
- Aux Input: schema (ISV) 代表由 Rastogi et al. (2020) 提出的 schema,其中包含 intent,domain-slot,value。schema graph 仅代表领域和槽位。ds 和 dsg 分别指的是对话状态(dialog state)和对话状态图(dialog state graph)。
- Level: 在《DST分类·根据状态级别分类》中提到了。
- SG 代表 slot gate,或者是 slot gate 的替代。√ 代表使用了最常见的 slot gate,× 代表没有使用任何 slot gate 机制。N/A 代表模型不必使用 slot gate。
- 模型排序:以 MultiWOZ 2.2 为准,如果没有结果,则按其他结果排序。
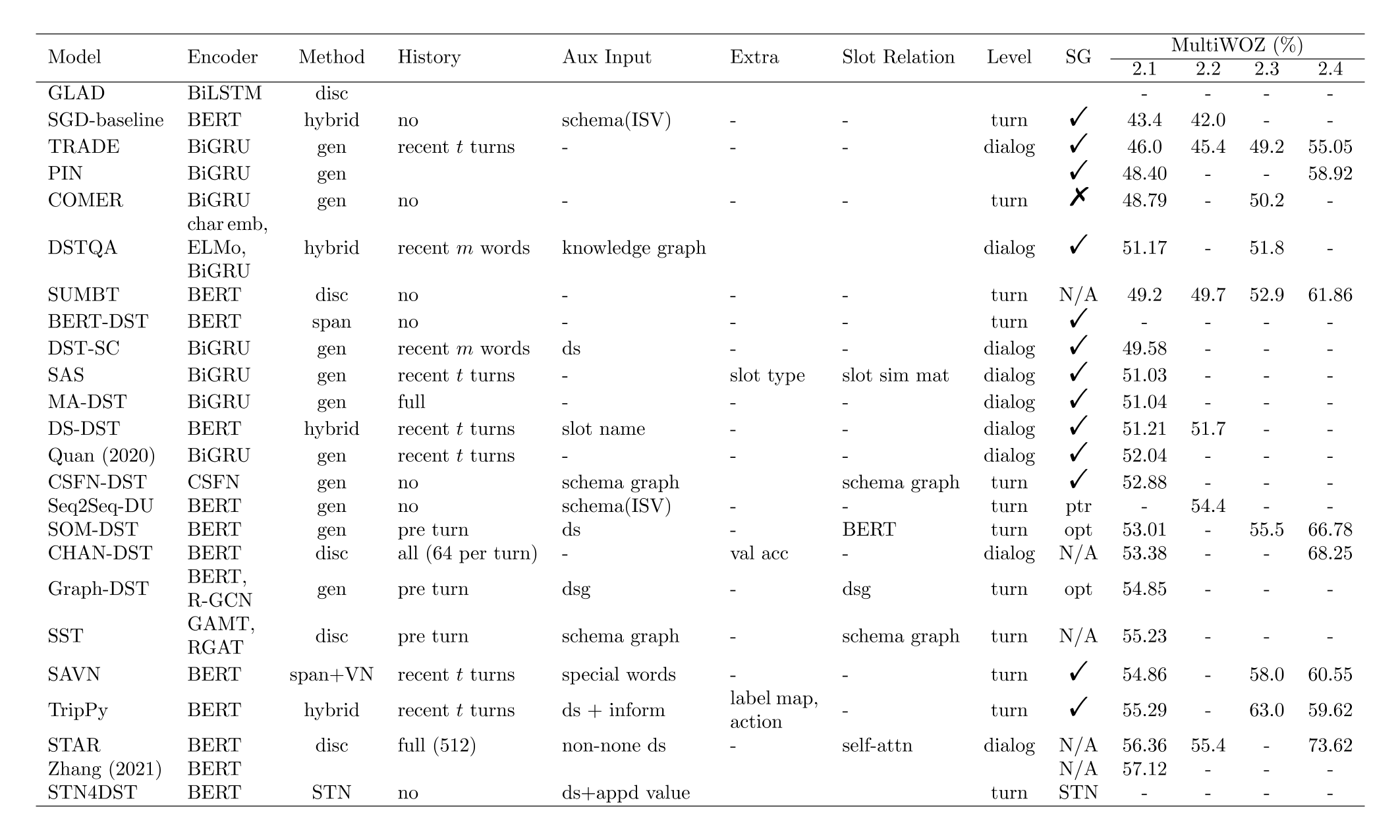
对于这张图在下面进行进一步解释:
问:cls 和 disc 有什么区别?
答:cls 指的是 classification model,disc 指的是 discriminative model。前者只是一个普通的线性分类器,后者指的是计算槽位表征和槽值表征之间的距离。本质上都是分类模型。对于这两个方法,模型的输入都是槽位表征,表征的获取方式类似,主要区别在于 cls 没有槽值表征,而 disc 通过 BERT 或其他特征提取器得到槽值的隐藏状态,我称之为槽值表征。从另一个视角来看,这两个方法几乎相同。试想将分类模型中的权重矩阵的每一行看作一个槽值表征,那么相对于 disc 来说,这些都是随机初始化的表征。所以二者的区别无非就两点:第一,cls 的槽值表征是随机的;第二,cls 多一个 bias。这一点其实在《DST 增强·槽位表征》一节提到了。我认为 disc 的优势在于它的槽值表征具有语义。实验表明,disc 大约好一个点。最后,disc 是个人命名,意味着槽位与槽值之间的判别,其它文献中应该没这种叫法。
问:dialog-level DST 和 history 有关系吗?
答:history 指的是对话历史。dialog-level DST 通常从头开始预测对话状态,如果没有对话历史,那么它自然无法预测前几轮的用户目标。这一点在《DST 分类·根据状态级别分类》中提到了。所以可能就有一种误解,dialog-level 的输入总是包含历史,turn-level DST 总是不包含历史。其实这是无所谓的。对话历史只是辅助信息,turn-level DST 照样可以输入全部的对话历史。
问:Aux Input 和 Extra 有什么区别?
答:Aux Input 代表辅助输入,Extra 指的是额外的信息。Aux Input 可以是图结构的对话状态,可以是槽位描述,也可以是自定义的特殊值。Extra 是与模型无关信息,例如 CHAN-DST 利用了验证集的准确率处理槽位的长尾问题,TripPy 利用 label map 在推理时进行后处理。